If you’re evaluating models for clinical-grade workflows, a medical AI comparison needs more than hype. I’ve piloted these systems in HIPAA/GDPR-bound environments and learned where each shines, where they stumble, and what it takes to deploy safely. Below, I map Med-PaLM 2, GPT-4, MedGemma, BioGPT, and Clinical BERT to real healthcare tasks, with benchmarks, access paths, and practical guardrails so you can de-risk integrations from day one.

Table of Contents
Med-PaLM 2: Advanced Medical AI for Clinical Insights
Key Features, Performance Benchmarks, and Accuracy
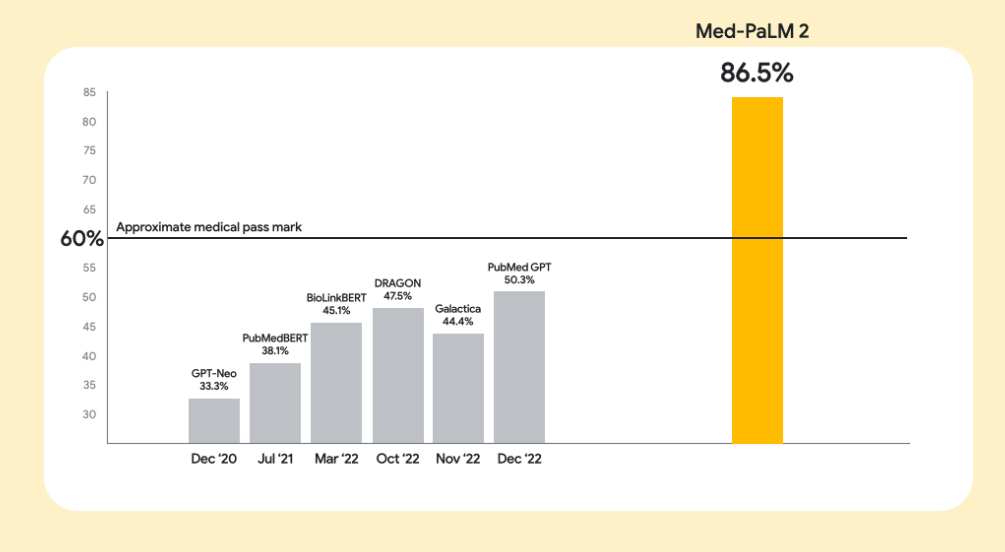
Med-PaLM 2 sits at the top for clinical reasoning. It hit 86.5% on MedQA (USMLE-style) and was the first to pass MedMCQA (72.3%). On PubMedQA, it reached 81.8% with self-consistency prompting. In physician evaluations, clinicians preferred its responses on 8/9 axes, emphasizing factuality and lower harm risk. Sources: Google Research Med-PaLM site, Nature Medicine study, Google Cloud Blog, PubMed Central.
Under the hood, it builds on PaLM 2 with domain fine-tuning, ensemble refinement, and chain-of-retrieval prompting, techniques I’ve found materially reduce hallucinations in long-context clinical questions.
Best Use Cases, Accessibility, and Deployment Tips
Best for: differential diagnosis support, high-stakes clinical Q&A, literature synthesis, and medical education. Accessibility is limited: it’s available to select Google Cloud partners (since April 2023), not public. It’s not a standalone diagnostic tool, physician oversight is non-negotiable.
My deployment notes: run rigorous prospective validation in your local setting (new specialties, patient mix, and EHR templates shift error profiles). Add guardrails: retrieval-augmented generation with source citation, policy-based refusals for out-of-scope asks, and real-time harm classifiers. Log model rationales and citations for auditability. Reference: Google Research guidance on ethical deployment.
GPT-4 in Healthcare: Generalist LLM for Medical Applications
Core Capabilities in Medical Tasks and Diagnostics
GPT-4 has consistently strong diagnostic breadth. In ED studies, it scored 1.76/2 vs residents at 1.59. For challenging cases, it identified the correct diagnosis in the top-6 61.1% vs physicians at 49.1%: for common scenarios, it included the correct diagnosis in the top-3 100% vs 84.3%. It solved 57% of complex medical case challenges, outperforming 99.98% of simulated human readers. GPT-4o also matched experienced ophthalmologists on differential accuracy while producing the most complete lists. Sources: NEJM AI and PubMed Central studies, Nature.
Strengths, Limitations, and Practical Considerations
Strengths: broad coverage across specialties, easy API access, and strong few-shot behavior. In delayed-diagnosis cases it achieved 66.7% primary accuracy, 83.3% when considering differentials.
Limitations: performance swings by specialty (ophthalmology and other narrow domains often favor specialist tools): risk of hallucinations: cost can spike at scale vs tuned local models. For privacy, I route through a BAA-backed tenant and enforce PHI redaction or in-VPC processing with role-based access. Source references: PMC, NEJM AI, domain variability reports.
MedGemma: Specialized LLM for Medical Expertise
Training Approaches for Domain-Specific Knowledge
MedGemma is purpose-built: 4B multimodal, 27B text-only, and 27B multimodal variants based on Gemma 3. It’s trained on medical text, Q&A, FHIR-like EHR data, and multiple imaging modalities (radiology, histopathology, ophthalmology, dermatology). Benchmarks: 4B hits 64.4% MedQA (excellent for a small open model): 27B text reaches 87.7% on MedQA, within ~3 points of DeepSeek R1 at roughly one-tenth inference cost. A board-certified radiologist judged 81% of 4B chest X-ray reports as sufficiently accurate for similar management. Sources: Google Research Blog, Developers docs, arXiv, MedGemma site.
Training approach: a medically optimized SigLIP image encoder plus medical data finetuning while retaining general capabilities. From my testing, LoRA adapters on hospital-specific vocab and imaging protocols yield fast wins without full retraining.
Multimodal Capabilities: Integrating Text and Medical Images
MedGemma’s SigLIP encoder is pre-trained on de-identified medical images: after fine-tuning it reached state-of-the-art RadGraph F1 30.3 for CXR report generation. It can integrate with agentic tools (FHIR generators, web search, Gemini Live) for end-to-end workflows. Caveat: early testers reported misses, e.g., a normal CXR read on a confirmed TB case, so it’s not clinical-grade out of the box. Always validate locally, add uncertainty estimation, and require radiologist sign-off. Sources: Google Research, GitHub notes, InfoQ.
BioGPT & Clinical BERT: Domain-Specific Biomedical Models
Research-Grade vs Clinical Applications
BioGPT set records on PubMedQA (78.2%: Large 81.0%) and excels at biomedical language generation and mining. It also posts strong relation extraction F1 on BC5CDR, KD-DTI, and DDI. ClinicalBERT variants, trained on MIMIC-III notes (~880M words), consistently beat general BERT for readmission prediction and medical concept recognition. Sources: Microsoft Research, Hugging Face, ScienceDirect, Nature Communications benchmark.
Reality check: encoder-only BERTs aren’t generators, but for structured clinical NLP (ICD extraction, problem lists, cohort finding), they’re rock solid and cheap.
Advantages for Specialized Medical Workflows
- Information extraction: tuned BioBERT/PubMedBERT reached ~65–70% accuracy in IE tasks (circa 2020) and still outperform many zero/few-shot LLMs on niche ontologies.
- Cost efficiency: small, domain-specific models can run on a single GPU and stay on-prem for HIPAA/GDPR. I reach for these when latency and PHI control trump open-ended chat.
Head-to-Head Medical AI Comparison
Performance Metrics Across Clinical and Diagnostic Tasks
- Med-PaLM 2: MedQA 86.5%: PubMedQA 81.8%. Expert-level clinical reasoning: limited access.
- GPT-4: ~mid-80s MedQA in public reports: ~75% PubMedQA-equivalent depending on prompt. Broad, strong diagnostics: variability by specialty.
- MedGemma 27B: MedQA 87.7%: multimodal strengths: requires fine-tuning for clinical safety.
- MedGemma 4B: MedQA 64.4%: highly efficient: good for edge or mobile.
- BioGPT: PubMedQA 81.0% (Large): best for research text generation.
- Clinical BERT: 65–70% IE tasks: excellent extraction, limited generation.
Resources: Hugging Face Medical LLM Leaderboard: Intuition Labs comparative diagnostics.
Cost, Accessibility, and Deployment Considerations
- Build costs: $60k–$100k for complex models: bespoke enterprise models can exceed $1M. Total programs often land $100k–$500k+ with up to 60% on data prep.
- Ops costs: cloud runs from ~$430–$650/month (simple) to $5k–$15k/month (complex): top-tier infra can hit $100k–$1M yearly.
- ROI: sector savings up to $360B: per-hospital savings grow from ~$1.6k/day in year one to ~$17.8k/day by year ten: imaging AI saves 3.3 hours/day. Sources: ITRex, Riseapps, Kenan Institute, Onix, Datafloq.
Decision Framework: Choosing the Best Medical LLM
Matching Models to Your Healthcare Use Case
- Clinical decision support: Med-PaLM 2 or GPT-4. Pair with retrieval, cite sources, enforce clinician-in-the-loop.
- Imaging: MedGemma 4B/27B: consider GPT-4o for cross-modal triage.
- Biomedical research: BioGPT for literature mining and generation.
- Clinical documentation/EHR: ClinicalBERT/Bio_ClinicalBERT for extraction and summarization.
- Patient-facing chat: GPT-4 or fine-tuned MedGemma with strict safety rails.
- Resource-constrained: MedGemma 4B or smaller BERT variants on a single GPU.
Key criteria I apply: define the problem with users first: confirm data availability: validate statistical performance, clinical utility, and economic impact. References: PMC implementation frameworks and Nature clinical validation guidance.
Hybrid Approaches, Future Trends, and Emerging Solutions
What’s working best for me now is hybrid intelligence: combine a local specialty model (BERT/MedGemma) for extraction or imaging with a generalist (GPT-4/Med-PaLM 2) for reasoning, all wrapped in retrieval, uncertainty scoring, and role-based access. Expect near-term gains from multimodal foundation models that fuse EHR, imaging, genomics, and wearables, plus agentic systems orchestrating coding, summarization, and worklist management. Regulatory oversight is tightening (e.g., foundation-model tagging, bias audits), so log everything and version datasets/models.
Implementation checklist I use:
- Start with a pilot and temporal/hold-out validation.
- Measure hallucination rate, citation coverage, adverse-action near-misses.
- Add guardrails: retrieval with source links, toxicity/harm filters, uncertainty prompts.
- Monitor drift: retrain or re-rank quarterly.
Sources: JMIR and ScienceDirect multimodal reviews, StartUs Insights on agentic AI, Intuition Labs on regulation.
Author note: I’m Andy Chen. I’ve implemented and audited LLMs in clinical pilots under HIPAA/GDPR: I do not have financial ties to the model providers cited above.
Legal Disclaimer: The content of this article is for educational purposes only.
The AI models discussed are assistive tools and cannot replace clinical judgment by qualified healthcare professionals.
All clinical deployment must comply with applicable local laws and regulations (e.g., HIPAA, GDPR).
Performance metrics cited are based on published studies or pilot testing, and may not reflect real-world clinical performance.




