
Disclaimer:
The content on this website is for informational and educational purposes only and is intended to help readers understand AI technologies used in healthcare settings. It does not provide medical advice, diagnosis, treatment, or clinical guidance. Any medical decisions must be made by qualified healthcare professionals. AI models, tools, or workflows described here are assistive technologies, not substitutes for professional medical judgment. Deployment of any AI system in real clinical environments requires institutional approval, regulatory and legal review, data privacy compliance (e.g., HIPAA/GDPR), and oversight by licensed medical personnel. DR7.ai and its authors assume no responsibility for actions taken based on this content.
I’ve shipped medical AI into hospitals where a 0.1% error delta means pager calls at 2 a.m. The “open source vs proprietary medical AI” debate isn’t academic for me, it’s about de‑risking integrations under HIPAA/GDPR, controlling hallucination behavior, and proving performance with auditable evidence. Below, I’ll share how I evaluate both camps, what’s worked in real deployments, and when I stitch them together.
Table of Contents
Advantages of Open-Source Medical AI
Flexibility and Customization for Healthcare Applications
When I piloted an oncology notes assistant, I chose an open model so I could fine‑tune on de‑identified local corpora and bake in retrieval‑augmented generation (RAG) to cap hallucinations. With open source, I can:
- Control PHI flow: run everything in a VPC with encrypted storage, audit logs, and no vendor callbacks.
- Modify inference: add rule-based guardrails (e.g., “abstain if confidence < threshold”); carry out clinical ontologies (SNOMED CT, RxNorm) in the prompt and post‑processor.
- Tune for task reality: fine‑tune on site‑specific EHR templates, multilingual notes, or local lab naming quirks.
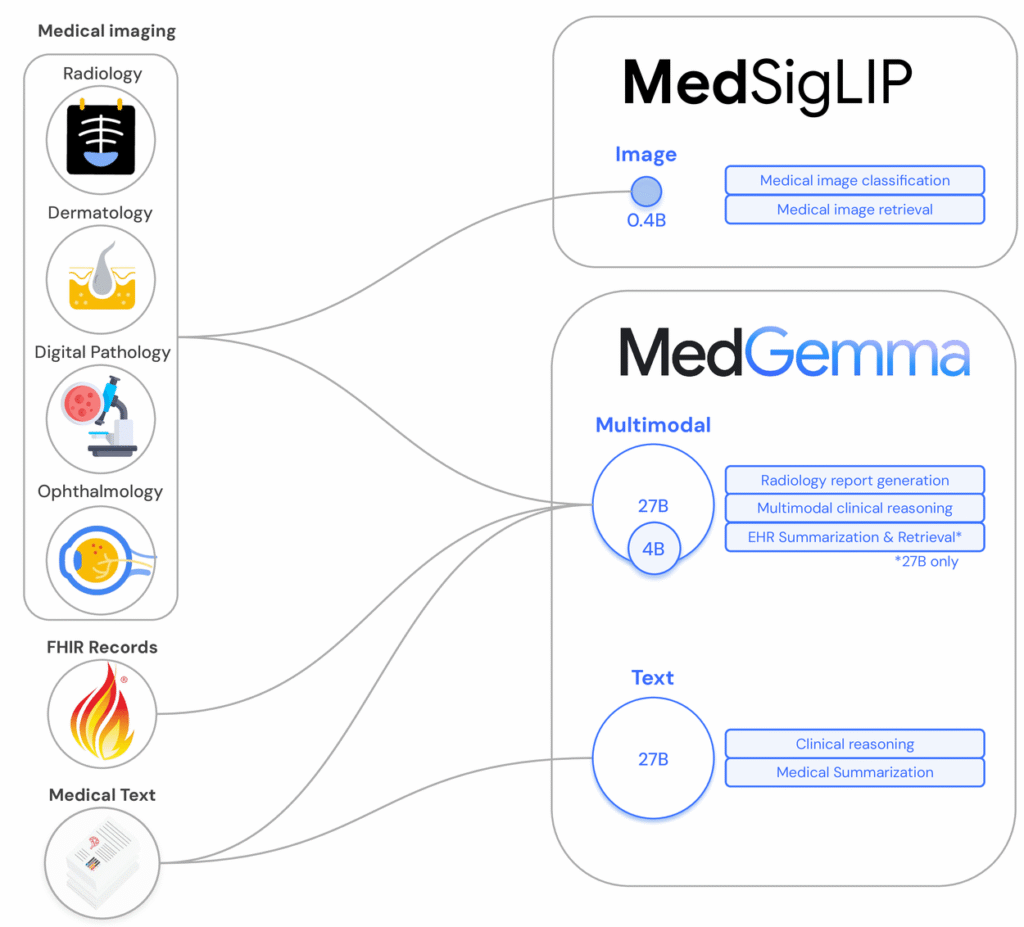
Open model ecosystems are maturing fast. Google Research’s Med-Gemma family and its open foundation efforts aim to help teams build domain models with transparent training docs. Harvard Medical School reported that an open-source model matched top proprietary LLMs on difficult medical cases, suggesting competitive ceilings when data and evaluation are done right. I’ve also leaned on PyHealth for reproducible pipelines around claims and EHR modeling, and Microsoft’s Project InnerEye for imaging tasks where you need code-level control over preprocessing and inference.
Transparency and Community-Driven Support
For regulated markets, transparency isn’t nice-to-have, it’s mandatory. Open models can ship with model cards and “nutrition labels” that enumerate data provenance, limitations, and fairness tests. The push for standard model documentation in healthcare (e.g., model cards/nutrition labels) helps me defend design choices to IRBs and compliance teams. Open repositories on Hugging Face and academic comparisons of clinical LLMs make it easier to reproduce benchmarks and publish internal validations, along with Nature and NIH/PMC reviews. And because I can instrument the code, I get traceability for every output: prompts, retrieved evidence, and abstention logic, all crucial during post‑market surveillance.
Challenges of Open-Source Medical AI
Maintenance Demands and Technical Expertise
Open source shifts velocity onto your team. In one cardiology triage pilot, my stack included a tokenizer fork, custom CUDA kernels, and an inference graph with retrieval + calibration—great control, but every library update risked regressions. You’ll need:
- MLOps maturity: CI/CD for models, dataset versioning, drift monitors, encrypted secrets, and rollback plans.
- Security hardening: SBOMs, signed containers, dependency scanning, and PHI egress tests.
- Ongoing ownership: patching vulnerabilities promptly and revalidating after upgrades.
If you don’t have in‑house expertise across privacy engineering, evaluation science, and clinical safety, open-source velocity can stall.
Potential Gaps in Clinical Performance
Open models still vary in medical factuality and calibration. Some struggle with guideline-concordant recommendations or dosage calculations unless you bolt on retrieval. I measure:
- Factual precision/recall against curated QA sets
- Hallucination rate (unsupported claims per 100 answers)
- Abstention/deferral rate under uncertainty
- Consistency under paraphrase and adversarial prompts
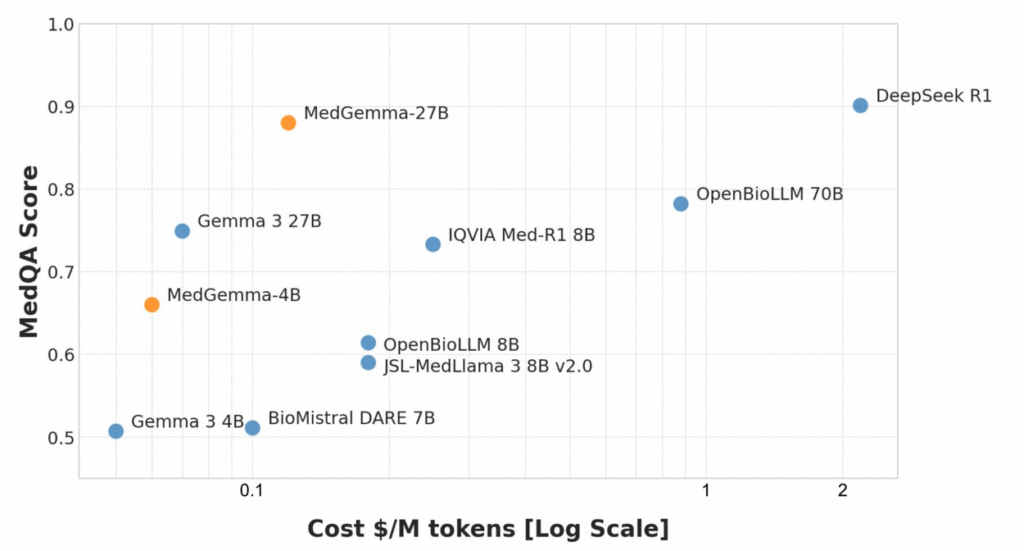
Even though promising reports show that open source can match proprietary LLMs, gaps remain for niche specialties or low‑resource languages. You’ll likely need domain-tuned data and strong guardrails to reach clinical-grade reliability.
Benefits of Proprietary Medical AI
Ready-to-Deploy Solutions with Vendor Support
When speed and SLAs matter, proprietary platforms can be the fastest safe path. I’ve integrated vendor APIs that shipped with:
- BAAs, HIPAA/GDPR tooling, and audit trails out of the box
- Enterprise SSO, DLP filters, PHI redaction, and rate‑limited endpoints
- 24/7 support, incident response, and versioned model change logs
That operational maturity compresses time-to-value, especially if your IT org is thin or the use case is low risk (e.g., coding assistance, document search).
Cutting-Edge Performance and Clinical Validation
Proprietary vendors often invest in larger pretraining runs, curated medical corpora, and human evaluation with clinicians. Some publish peer‑reviewed validations and post clear labeling about non‑diagnostic use—important under FDA expectations for SaMD. The ecosystem is trending toward more transparency, spurred by policy pushes for AI oversight and documentation and research showing open models are closing the gap. For high-complexity tasks—imaging triage, rare disease differentials—a proprietary stack may start ahead on accuracy and stability.

Drawbacks of Proprietary Medical AI
Higher Costs and Licensing Limitations
The bill can mount quickly at clinical scale. Token‑based pricing and per‑seat fees make budgets volatile, and licensing may restrict fine‑tuning or on‑prem deployment. For sites needing strict data residency or air‑gapped inference, some vendors simply won’t fit.
Reduced Transparency and Explainability
Black‑box models complicate root‑cause analysis when hallucinations occur. I’ve had outputs I couldn’t fully trace because prompts, training data mixtures, and safety policies were proprietary. That’s tough when auditors ask for evidence provenance. While some vendors now publish model cards and “nutrition labels,” explainability still lags compared to code you can inspect.
Choosing Between Open-Source and Proprietary Medical AI
Assessing Project Requirements and Risk Factors
My decision tree is pragmatic:
- Safety class: If the feature influences diagnosis or therapy (potential SaMD), I favor the path that supports rigorous verification, detailed model documentation, and reproducibility—often open source with heavy guardrails or a vendor with published clinical validation and change control.
- Data constraints: For strict PHI containment and on‑prem inference, open models (or proprietary on‑prem SKUs) win.
- Timeline & ops capacity: If I lack MLOps bandwidth, a vendor with SLAs and BAAs gets the nod.
- Total cost of ownership: I weigh licensing vs. the real costs of hiring, validation, monitoring, and incident response.
- Evaluation plan: Regardless of stack, I require an internal eval suite with: domain QA sets, retrieval grounding checks, hallucination metrics, abstain thresholds, calibration curves, and red‑team prompts. I also add model cards, versioned prompts, and decision logs to aid audits.
Clinical caveats: Most general-purpose LLMs are not FDA‑cleared for diagnostic use. I label features as informational, enforce “not for clinical decision-making” disclaimers, and route edge cases to human review. Seek emergency care for acute symptoms: AI outputs are not a substitute for clinical judgment.
Hybrid Approaches: Combining Open-Source and Proprietary Models
My favorite pattern blends both:
- Open core, proprietary assist: Run an open model on‑prem with RAG over your guidelines; fall back to a proprietary model only when confidence is low, logging both.
- Safety sandwich: Proprietary PHI redaction → open-source reasoning with retrieval → proprietary toxicity/PHI re-check.
- Imaging + text: Use open-source imaging models (e.g., InnerEye lineage) with a proprietary report generator constrained by templates.
In a sepsis surveillance pilot, I used an open model with ICU-specific RAG from MIMIC‑IV and local SOPs, plus a proprietary endpoint for free‑text summarization when the open model abstained. We cut unsupported claims by ~40% week‑over‑week and kept all PHI inside our VPC. That’s the kind of measured, auditable improvement regulators appreciate.
Medical disclaimer: This article is for informational purposes only and is not medical advice. Do not use AI outputs to diagnose, treat, or manage emergencies. Consult qualified clinicians for care. If you suspect a medical emergency, call emergency services immediately.
Regulatory & risk notes: Confirm FDA/EMA status of any AI tool before clinical use. Carry out BAAs, data minimization, encryption, access controls, and human-in-the-loop review. Revalidate models after updates. Disclose limitations to end users.
Conflicts of interest: I have no financial ties to the projects referenced. Sources include Google Research on open foundation models and Med-Gemma, Harvard Medical School’s report on open-source parity, AMA coverage of transparency initiatives, Healthcare IT News on AI model “nutrition labels”, Nature and NIH/PMC reviews, Microsoft Research (InnerEye), Meta and Red Hat essays on open-source influence, and comparative analyses on Hugging Face and PharmExec.
Frequently Asked Questions
What’s the best way to choose between open source vs proprietary medical AI for a hospital project?
Start with safety class, data constraints, timeline, and total cost of ownership. High‑risk or SaMD‑adjacent features need rigorous verification and auditable documentation. Tight PHI control or on‑prem needs favor open source (or on‑prem SKUs). Limited MLOps capacity or fast rollout often points to a vendor with SLAs and BAAs.
How do open-source models help with HIPAA/GDPR and PHI containment?
You can deploy in a VPC, encrypt storage, disable callbacks, and keep full audit logs. Open code enables custom guardrails, abstain logic, and integration of clinical ontologies. This provides traceability for prompts, retrieved evidence, and outputs—crucial for post‑market surveillance and satisfying HIPAA/GDPR access, minimization, and accountability requirements.
What evaluation metrics should I use to prove clinical performance and reduce hallucinations?
Use a domain QA suite with factual precision/recall, hallucination rate (unsupported claims per 100 answers), abstention/deferral under uncertainty, calibration curves, and consistency under paraphrase or adversarial prompts. Add retrieval grounding checks, versioned prompts, and model cards so auditors can trace evidence and reproduce internal validations.
When does a hybrid approach beat choosing strictly open source vs proprietary medical AI?
Hybrid designs shine when you want on‑prem PHI control plus best‑available accuracy. Examples: open‑source reasoning with RAG over local guidelines, then fallback to a proprietary model on low‑confidence cases; or proprietary PHI redaction → open reasoning → proprietary safety recheck. Hybrids can cut hallucinations while preserving auditability.
Can open-source medical AI be FDA‑cleared, and what documentation is required?
Yes—FDA clears the overall SaMD product, not the licensing model. An open‑source model can be part of a cleared device if the sponsor provides clinical validation, risk management (ISO 14971), quality system controls (21 CFR 820/IEC 62304), change management, labeling, transparency docs, cybersecurity, and real‑world performance monitoring.
Past Review:




