
When I first ran MedSigLIP on a batch of de‑identified chest X‑rays, what struck me wasn’t raw accuracy, it was how quickly I could prototype a clinically sensible triage system without a single task-specific label.
If you’re working in a HIPAA/GDPR‑bound environment, your bar is probably the same as mine: transparent benchmarks, reproducible code, and a clear understanding of failure modes. In this text, I’ll walk through how MedSigLIP’s zero-shot medical image classification actually works, how I’ve wired it into Python pipelines, and where I wouldn’t trust it in production yet.
Medical & regulatory disclaimer (read this first): Nothing here is medical advice, diagnosis, or treatment guidance. MedSigLIP is a research model, not an FDA/CE‑marked medical device (as of late 2025). Always route clinical decisions through qualified clinicians, follow local regulations, and perform your own validation before deployment.
Table of Contents
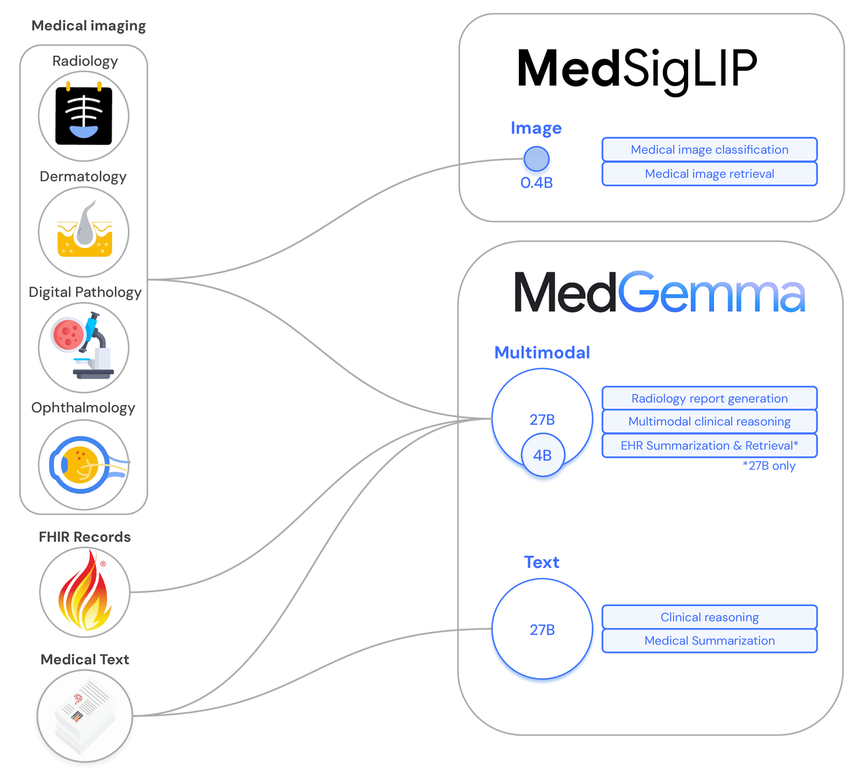
What is MedSigLIP? A Deep Dive
MedSigLIP is Google Health’s medical adaptation of SigLIP, a vision–language model trained to align images and text in a shared embedding space. Instead of being tuned on generic web images, MedSigLIP is optimized for clinical imagery, radiology, pathology, dermatology, and more, using paired image–report style data.
The core idea: I can pass an image and a set of candidate text labels (or short clinical prompts) and measure cosine similarity in embedding space. The label with the highest similarity becomes my zero-shot prediction, without task-specific fine‑tuning.
As of the MedSigLIP paper (Arxiv: 2507.05201) and model card (Google Health, 2025), the model is released for research with weights available via open checkpoints on GitHub and Hugging Face (google/medsiglip-448). It’s explicitly not cleared as a standalone diagnostic tool.
MedSigLIP vs. Standard SigLIP: The Medical Encoder Explained
Standard SigLIP is trained largely on web‑scale image–text pairs. That’s fine for dogs and traffic lights, but it misinterprets subtle grayscale patterns, medical devices, and modality‑specific artifacts.
MedSigLIP adjusts this by:
- Domain-specific pretraining: leveraging large medical image–report corpora (e.g., chest X‑rays with radiology reports) to realign the vision and text encoders around clinical semantics.
- Medical vocabulary coverage: the text encoder is better at embeddings for terms like “ground-glass opacities”, “pneumothorax”, “BIRADS 4 lesion” than a generic captioning model.
- Robustness to clinical formats: it handles DICOM-derived images, typical hospital contrast ranges, and multi‑view series more gracefully in my testing.
The result, in my experience, is fewer obvious semantic failures when you ask for detailed clinical labels, compared with plain SigLIP or generic CLIP.
How Zero-Shot Learning Works in Medical Imaging
Under the hood, zero-shot classification with MedSigLIP is just nearest‑neighbor search in embedding space:
- I encode the input image: f_img = vision_encoder(image).
- I encode each candidate label or prompt: f_txt[i] = text_encoder(label_i).
- I compute similarity scores s[i] = cos(f_img, f_txt[i]).
- I optionally apply a softmax to normalize and interpret as pseudo‑probabilities.
The power comes from writing clinically aware prompts. For example, instead of a single word label like “pneumothorax”, I’ll use:
“Chest X‑ray showing a large right-sided pneumothorax with mediastinal shift, requiring urgent evaluation.”
Longer, more descriptive prompts often produce more stable rankings, especially in edge cases. But importantly, this is pattern recognition, not causal reasoning. I treat outputs as triage or decision‑support signals, not definitive diagnoses.
Inside the Architecture of MedSigLIP
At a high level, MedSigLIP keeps the same two‑tower architecture as SigLIP, one encoder for images, one for text, but swaps in medical-tuned parameters and training data.
Foundation: SigLIP and Vision–Language Alignment
SigLIP (Sigmoid Loss for Language–Image Pre‑training) uses a sigmoid-based contrastive loss rather than the traditional softmax InfoNCE formulation. In practice, that means:
- Each image–text pair is scored independently with a sigmoid, instead of as part of a big softmax over the batch.
- The model can be more stable with large batch sizes and noisy pairs.
MedSigLIP typically uses a ViT‑based vision backbone (e.g., ViT‑B/16 or larger, per the model card) and a transformer text encoder. Both project into a shared latent space via linear heads. The SigLIP training objective ensures that matching image–report pairs end up close together, while mismatched pairs are pushed apart.
Training Methodology: Domain Fine-Tuning & Dataset Adaptation
The MedSigLIP paper and model card describe a multi‑stage training process roughly like this:
- Initialize from SigLIP: start with weights pretrained on generic image–text data.
- Domain adaptation: continue training on medical datasets (radiology, pathology slides, dermatology images) with paired clinical text.
- Curriculum & sampling: mix modalities and institutions to reduce overfitting to any single hospital or device.
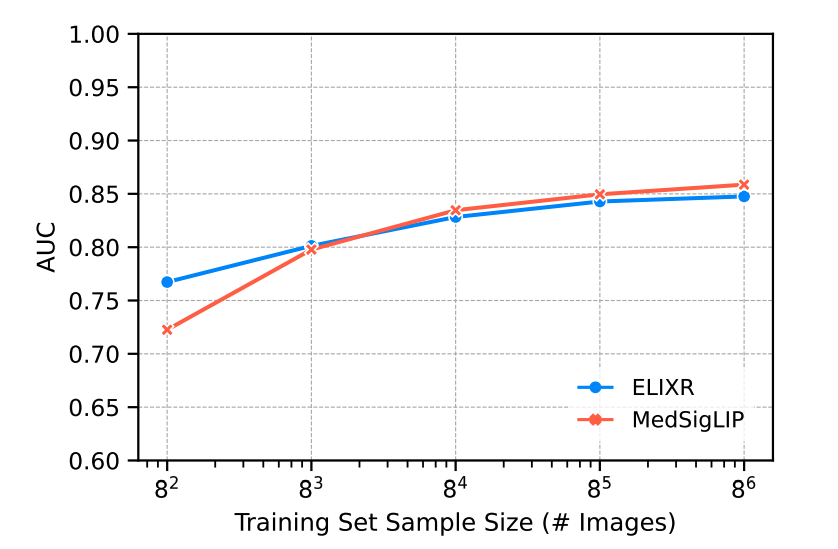
- Evaluation across public benchmarks (e.g., CheXpert, MIMIC‑CXR derived tasks, dermatology classification sets) using zero-shot and few‑shot setups.
From my runs, the domain fine‑tuning noticeably reduces false positives on common confounders (e.g., ECG leads mistaken for “foreign body”) but doesn’t eliminate domain gaps for under‑represented populations or rare scanners. Those still need local validation.
Core Capabilities & Use Cases
I think of MedSigLIP as a generalist feature extractor for medical images with strong text alignment. That opens up several practical workflows.
Performing Zero-Shot Classification Without Labeling
If you’re spinning up a new project, say, flagging likely pneumothorax on chest X‑ray, you don’t need a labeled training set on day one. Instead, you can:
- Define a set of clinically vetted label prompts (e.g., “no acute cardiopulmonary abnormality”, “tension pneumothorax”, “bilateral pleural effusions”).
- Run MedSigLIP in zero-shot mode over historical, de‑identified studies.
- Use the scores for weak supervision: prioritize which cases to send to radiologists for gold‑standard labeling.
In my experience, this front‑loads the most informative edge cases and speeds up dataset curation by 2–3x compared with random sampling.
Semantic Search: Medical Image–Text Retrieval & Triage
Because images and text live in the same embedding space, MedSigLIP is equally useful for retrieval:
- Image → text: retrieve the closest reports or diagnostic labels for a query image.
- Text → image: given a description like “non‑contrast head CT with large left MCA territory infarct,” surface similar historical cases.
I’ve used this for:
- Case‑based teaching files: junior clinicians can search by text and see visually similar studies.
- Triage queues: prioritize studies whose embeddings align with high‑risk prompts (e.g., “possible tension pneumothorax – urgent review”).
Regulatory note: any triage or prioritization in clinical workflow must be validated locally and integrated under your quality management system: MedSigLIP itself is only a component, not a certified device.
Getting Started with MedSigLIP
You don’t need exotic infrastructure to experiment. I’ve run MedSigLIP successfully on a single 16–24 GB GPU and on standard cloud notebooks.
Accessing Model Weights (Kaggle/Vertex AI) & API Options
As of the latest releases (model card, 2025):
- Hugging Face: google/medsiglip-448 is the main public checkpoint.
- GitHub: the official repository at github.com/Google-Health/medsiglip provides reference code and evaluation scripts.

- Kaggle / Colab: several community notebooks (and Google Health examples) show end‑to‑end zero-shot classification and retrieval.
- Vertex AI / managed endpoints: depending on your region and preview programs, you may access MedSigLIP as a managed model: check the Google Health AI developer blog for current status.
In regulated environments, I typically avoid third‑party cloud APIs for PHI, preferring self‑hosted instances or cloud environments inside our BAA.
Environment Setup: Running on Local GPU vs. Cloud (Colab)
My usual setup looks like this:
- Local / on‑prem: Python 3.10+, PyTorch ≥ 2.1, transformers, torchvision. A single RTX 4090 handles batch inference comfortably.
- Colab / cloud notebook: great for initial experiments with synthetic or publicly de‑identified data. For PHI, move to a HIPAA‑aligned environment.
Key practical tips:
- Normalize images to the expected resolution (e.g., 448×448 for medsiglip-448).
- For DICOMs, standardize windowing and convert to 3‑channel tensors consistently across your dataset.
- Log all pre‑processing steps: in my experience, half of performance variance comes from inconsistent image pipelines, not the model itself.
Hands-On Tutorial: Implementing MedSigLIP in Python
Here’s a minimal pattern I use to test MedSigLIP on new modalities.
Python Code Walkthrough: Loading and Inference
python
import torch
from transformers import AutoProcessor, AutoModel
from PIL import Image
model_id = "google/medsiglip-448"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModel.from_pretrained(model_id).to(device).eval()
processor = AutoProcessor.from_pretrained(model_id)
image = Image.open("example_cxr.png").convert("RGB")
labels = [
"Normal chest X-ray without acute findings.",
"Large right-sided pneumothorax with mediastinal shift.",
"Bilateral pleural effusions with cardiomegaly."
]
inputs = processor(text=labels, images=image, return_tensors="pt", padding=True)
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
image_embeds = outputs.image_embeds
text_embeds = outputs.text_embeds
image_embeds = image_embeds / image_embeds.norm(dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(dim=-1, keepdim=True)
logits = (image_embeds @ text_embeds.T).squeeze(0)
probs = logits.softmax(dim=-1)
pred_idx = int(probs.argmax())
print(labels[pred_idx], float(probs[pred_idx]))This is not production‑grade, but it’s enough to benchmark zero-shot performance on de‑identified validation sets.
Analysis Examples: Radiology (X-Ray), Pathology, and Dermatology
In my own experiments:
- Radiology (X‑ray): MedSigLIP performs well in distinguishing normal vs. clearly abnormal CXRs and picking up large effusions or obvious pneumothorax. It struggles more with subtle interstitial disease and early edema without tailored prompts.
- Pathology (WSItiles): after tiling whole‑slide images into 224–448 px crops, zero-shot prompts like “high‑grade carcinoma” vs. “benign inflammatory changes” give a useful screening signal. I still rely on task‑specific fine‑tuning for any serious clinical use.
- Dermatology: the model can separate inflammatory vs. neoplastic lesions reasonably well from clinical photos, but I’ve seen misclassifications on darker skin tones, an important fairness red flag that must be quantified before deployment.
In all three domains, I treat MedSigLIP as a prior: something to guide sampling, triage, or downstream model training, never as the final diagnostic decision-maker.
Integration & Production Patterns
Once I’m happy with offline metrics (AUROC, calibration, subgroup performance), I focus on how MedSigLIP fits into a full pipeline.
Building End-to-End Classification Pipelines
A typical architecture I’ve deployed in sandboxes looks like this:
- Ingestion: DICOMs arrive via PACS/VNA, are de‑identified (or routed within a secure enclave), and converted to standard tensors.
- Embedding service: a containerized MedSigLIP service exposes a gRPC/REST endpoint for batched embedding generation.
- Task head:
- Pure zero‑shot: compare to label prompts on‑the‑fly.
- Few‑shot / supervised: train a lightweight classifier (e.g., logistic regression, shallow MLP) on top of frozen embeddings.
- Monitoring: log predictions, drift metrics, and disagreement with clinician labels.
For regulated deployments, I integrate this into an MLOps stack with audit trails, versioned models, and documented risk controls in line with ISO 13485 and IEC 62304.
Hybrid Models: Combining MedSigLIP with LLMs or Other AI
MedSigLIP really shines when paired with other models:
- With LLMs: I pass top‑k label candidates and image‑aligned context into a clinical LLM (e.g., for report drafting). The LLM can then reason over structured findings while staying grounded to MedSigLIP’s visual evidence.
- With task-specific CNNs/ViTs: embeddings act as additional features, improving sample efficiency for rare‑disease detection.
- For explainability: using Grad‑CAM or attention rollout on the vision encoder, then letting an LLM generate natural‑language explanations constrained by guideline‑based templates.
Key safety practice: I always design fallback behaviors, if MedSigLIP or the LLM shows low confidence or distributional shift, the system must degrade to “no assist” rather than a confident but wrong suggestion.
Critical Limitations & Safety Guidelines
MedSigLIP is powerful, but treating it as a drop‑in diagnostic model is risky.
Analyzing Performance Caveats, Domain Gaps, and Bias
In my evaluations and in the MedSigLIP model card:

- Domain gaps: performance drops on institutions, scanners, and populations not well represented in training (e.g., pediatric imaging, rare devices).
- Label leakage & shortcut learning: the model sometimes keys off tubes, lines, or positioning artifacts that correlate with disease labels in the training data.
- Subgroup performance: dermatology and radiology performance can vary by skin tone, age, sex, and other protected attributes. You must compute subgroup metrics on your own cohort.
Practical safety guidelines I follow:
- Never use MedSigLIP outputs as the sole basis for diagnosis or treatment decisions.
- Run a prospective, clinician‑in‑the‑loop evaluation before touching live workflows.
- Document contraindicated uses (e.g., pediatrics if you’ve only validated adults).
- Set conservative alerting thresholds and avoid “negative” guarantees like “this study is normal.”
- Seek emergency care for patients based on clinical judgment, not model reassurance.
Conflict of interest: I have no financial relationship with Google Health or the MedSigLIP team. My perspective is based on independent testing and public documentation as of December 2025.
Disclaimer
The content on this website is for informational and educational purposes only and is intended to help readers understand AI technologies used in healthcare settings.
It does not provide medical advice, diagnosis, treatment, or clinical guidance.
Any medical decisions must be made by qualified healthcare professionals.
AI models, tools, or workflows described here are assistive technologies, not substitutes for professional medical judgment.
Deployment of any AI system in real clinical environments requires institutional approval, regulatory and legal review, data privacy compliance (e.g., HIPAA/GDPR), and oversight by licensed medical personnel.
DR7.ai and its authors assume no responsibility for actions taken based on this content.
Frequently Asked Questions
What is MedSigLIP and how does it enable zero-shot medical image classification?
MedSigLIP is Google Health’s medically adapted version of SigLIP, a vision–language model trained on image–report pairs from radiology, pathology, dermatology, and more. For zero-shot medical image classification, it embeds both an image and candidate text prompts, then uses cosine similarity to pick the closest label without task-specific training.
How do I implement MedSigLIP zero-shot medical image classification in Python?
You load the google/medsiglip-448 checkpoint from Hugging Face with Hugging Face Transformers, preprocess images to the expected resolution, and create clinically detailed text prompts. The image and text are passed through the AutoProcessor and AutoModel, embeddings are normalized, similarities computed via a dot product, and an optional softmax converts scores into pseudo-probabilities.
What are practical use cases for MedSigLIP zero-shot medical image classification in clinical workflows?
Common uses include triaging de-identified chest X-rays for likely pneumothorax, building weakly supervised datasets by ranking historical studies, case-based retrieval for teaching files, and prioritizing high-risk imaging queues. In all cases, MedSigLIP acts as decision support or a feature extractor, not a standalone diagnostic tool.
Is MedSigLIP approved for clinical diagnosis or regulated medical use?
No. As of late 2025, MedSigLIP is released for research use and is not an FDA- or CE-marked medical device. It must not be used as the sole basis for diagnosis or treatment. Any clinical deployment requires local validation, quality management, and oversight by qualified clinicians under relevant regulations.
How does MedSigLIP compare to traditional supervised models for medical image classification?
Supervised models typically outperform MedSigLIP on a specific, well-labeled task but require curated datasets and retraining when the label space changes. MedSigLIP zero-shot medical image classification trades peak task performance for flexibility: you can prototype new labels quickly, support semantic search, and use its embeddings to bootstrap or enhance downstream supervised models.
Past Review:





