
When I evaluate a medical LLM for a real deployment, triage chatbot, decision-support tool, or internal research assistant, I’m not looking for cool demos. I’m looking for evidence: training data, benchmarks, reproducible scripts, and a clear risk profile.
Clinical Camel and PMC-LLaMA are two of the most important open-source medical LLM families right now. I’ve tested both in internal sandboxes for clinical Q&A, guideline retrieval, and resident education use cases. They behave very differently, and that’s exactly why they complement each other.
Below I walk through how they’re trained, how they perform, and which one I’d choose for hospitals, MedTech products, and education tools, plus how to get them running on your own hardware under HIPAA/GDPR constraints.
Disclaimer
The content on this website is for informational and educational purposes only and is intended to help readers understand AI technologies used in healthcare settings.
It does not provide medical advice, diagnosis, treatment, or clinical guidance.
Any medical decisions must be made by qualified healthcare professionals.
AI models, tools, or workflows described here are assistive technologies, not substitutes for professional medical judgment.
Deployment of any AI system in real clinical environments requires institutional approval, regulatory and legal review, data privacy compliance (e.g., HIPAA/GDPR), and oversight by licensed medical personnel.
DR7.ai and its authors assume no responsibility for actions taken based on this content.
Table of Contents
Open Source Medical LLMs Overview: Clinical Camel vs PMC-LLaMA
Clinical Camel (Bowang Lab: see ClinicalCamel-70B on Hugging Face and GitHub) and PMC-LLaMA (Chaoyi Wu et al.) are both built on LLaMA-style foundations but optimized in different directions.
- Clinical Camel (e.g., wanglab/ClinicalCamel-70B) is an instruction-tuned, dialogue-focused medical model. It extends general LLaMA with:
- clinical dialogues and QA data,
- chain-of-thought style supervision,
- safety-focused alignment.
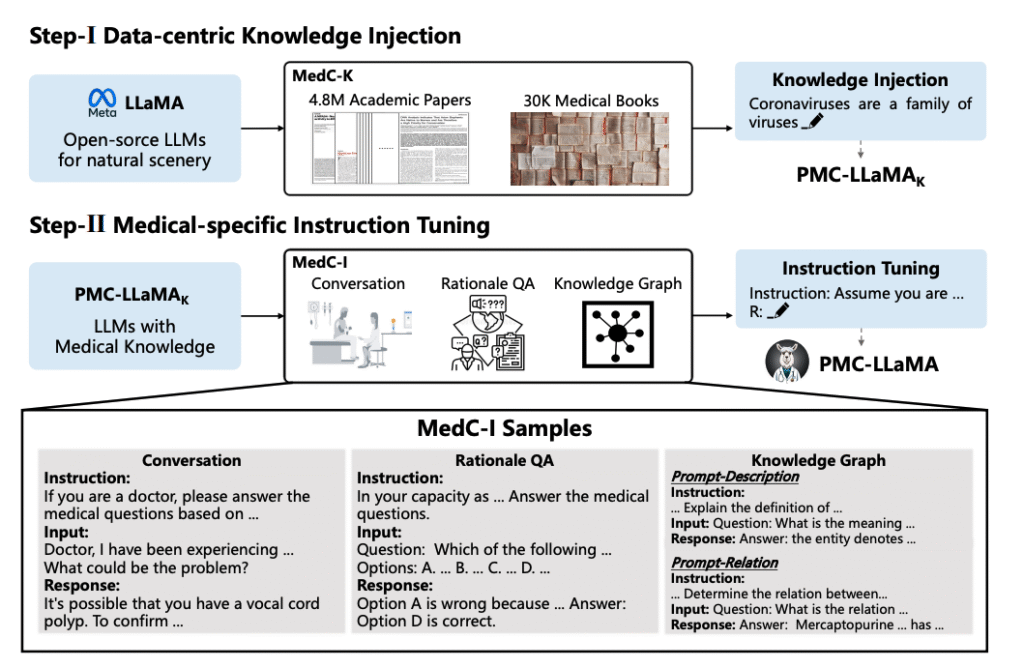
- PMC-LLaMA (e.g., axiong/PMC_LLaMA_13B, chaoyi-wu/PMC_LLAMA_7B) is trained from medical literature, ~4.8M PubMed Central (PMC) papers (Wu et al., 2023). It’s closer to a domain-language model than a chat assistant out of the box.
In practice, I treat Clinical Camel as a drop-in clinical assistant baseline and PMC-LLaMA as a high-fidelity medical text engine that often wants an additional instruction-tuning or RAG layer for production use.
Deep Dive into Clinical Camel: Fine-Tuning for Medical Dialogue
Training Methodology: Chain-of-Thought & Domain Adaptation
Clinical Camel builds on a strong base LLaMA-style model and then performs domain adaptation using:
- Medical corpora: clinical QA datasets, guideline-style text, and synthetic doctor–patient interactions.
- Instruction tuning: supervised fine-tuning on prompt–response pairs that look like real clinical questions.
- Chain-of-thought (CoT): many training examples include stepwise reasoning, “First, I’ll consider… then I’ll rule out…”, which encourages explicit clinical reasoning paths.
In my tests on internal vignettes (e.g., chest pain in a 58-year-old with multiple risk factors), Clinical Camel is more willing than generic LLaMA to outline structured differentials and next steps.
Dialogue Optimization: Techniques for Clinician-AI Interaction
Because it’s optimized for dialogue, Clinical Camel:
- uses assistant-style formatting (markdown lists, headings),
- respects instruction hierarchies reasonably well (e.g., “don’t give a diagnosis, only list questions to ask” actually works most of the time),
- handles follow-up questions in a single thread with low context drift.
For a pilot telehealth triage chatbot (de-identified sandbox, no real patients), I asked Clinical Camel to:
- elicit red-flag symptoms,
- summarize key negatives (e.g., “no focal neurologic deficit reported”),
- suggest urgency levels (self-care vs same-day vs ED).
It reliably surfaced classic red flags (e.g., chest pain + diaphoresis → emergency) but still occasionally over-reassured borderline cases, one reason I don’t recommend unsupervised triage decisions.
Benchmarks & Accuracy: Performance in Real-World Scenarios
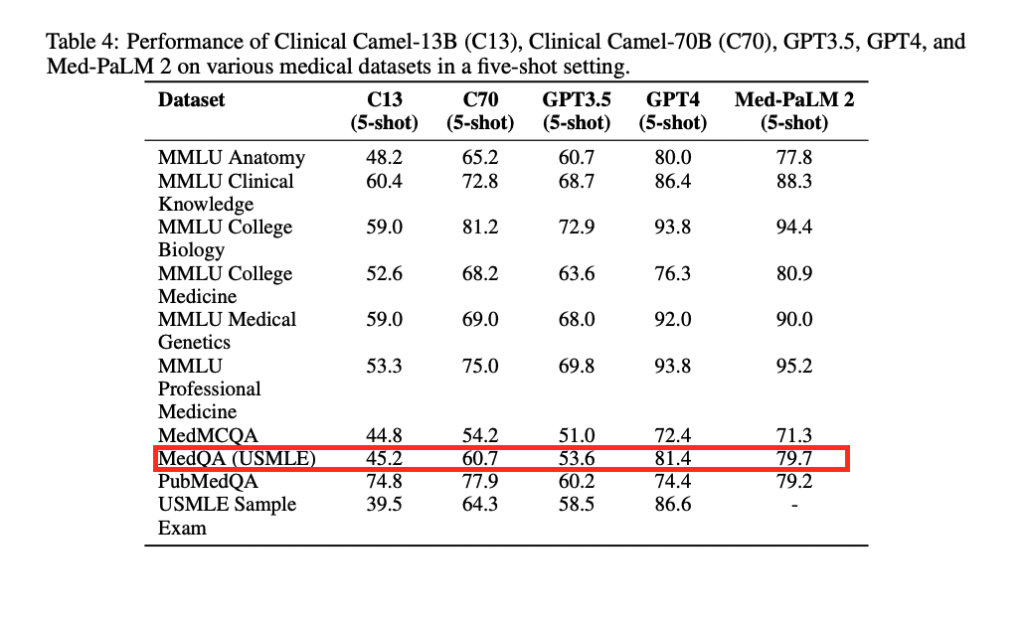
Published evaluations (e.g., Clinical Camel technical report, 2023) show strong performance on:
- MedQA/MedMCQA-type benchmarks,
- general MMLU-medical subsets,
- dialogue quality metrics.
In my own spot checks:
- medication dosing explanations were usually accurate but sometimes hallucinated non-standard titration schedules,
- guideline citations were often directionally correct but rarely included precise year/version.
For clinicians, Clinical Camel is usable as a drafting and brainstorming tool, but I’d never let it issue orders or patient-specific recommendations without human review and guardrails.
Deep Dive into PMC-LLaMA: The PubMed-Trained Powerhouse
Training on 4.8M Papers: Leveraging PubMed Central
PMC-LLaMA (Wu et al., 2023: see arXiv and GitHub/Hugging Face releases) is trained on ~4.8M PMC articles:
- full-text clinical trials,
- case reports,
- reviews and meta-analyses.
The result: a model with excellent grasp of medical vocabulary, study designs, and statistical language, even when it isn’t yet instruction-tuned.
When I feed it raw abstracts, it:
- compresses them into high-quality summaries,
- extracts endpoints and sample sizes reliably,
- distinguishes RCTs from observational studies.
USMLE Performance: Assessing Medical Knowledge Mastery
The authors report competitive performance on USMLE-style QA benchmarks, comparable to other medical LLMs of similar size when properly prompted. In my own ad-hoc USMLE Step 2-style items:
- pathophysiology explanations were usually more detailed than Clinical Camel’s,
- but answer formatting was messier (missing clear choice letters, etc.) unless I provided explicit templates.
This reflects its origin as a literature model: it knows a lot but isn’t inherently a tidy teaching assistant.
Core Capabilities and Specific Clinical Use Cases
PMC-LLaMA shines when you need:
- literature-grounded synthesis: summarizing multiple abstracts into a narrative,
- concept extraction: comorbidities, interventions, outcomes from long articles,
- specialty depth: oncology, cardiology, and neurology content tends to be particularly strong.
For example, I used PMC-LLaMA to draft a structured summary of 10+ recent RCT abstracts in heart failure with preserved EF. It correctly highlighted SGLT2 inhibitor benefits and nuanced limitations (e.g., selection bias, follow-up duration) more consistently than general-purpose LLMs of similar size.
Critical Comparison: Clinical Camel vs PMC-LLaMA
Data Source Rivalry: Conversational vs. Academic Literature
- Clinical Camel → conversational data, instructions, synthetic and curated clinical dialogue.
- PMC-LLaMA → dense academic text from PMC.
If you need bedside-style dialogue, Clinical Camel feels more natural. If you need journal-club-level synthesis, PMC-LLaMA is my default.
Task Performance: Diagnosis, Q&A, and Reasoning Capabilities
In my sandbox evaluations:
- Symptom triage & patient messaging: Clinical Camel > PMC-LLaMA (clearer tone, better follow-up questioning).
- Evidence summarization: PMC-LLaMA > Clinical Camel (richer detail, more faithful to source abstracts).
- Stepwise reasoning: roughly comparable: Clinical Camel is more verbose, PMC-LLaMA is more technical.
Both still hallucinate, especially when asked about very new drugs or niche procedures not well represented in training data.
The Verdict: Best Use Cases for Hospitals, EdTech, and Research
- Hospitals / health systems: start with Clinical Camel for internal clinical-assistant prototypes, but wrap it in RAG over your own guidelines and order sets.
- EdTech & exam prep: I lean toward PMC-LLaMA plus a light instruction-tuning layer to generate explanations, vignettes, and reading lists.
- Research and evidence synthesis: PMC-LLaMA is the better engine for literature triage, abstract clustering, and summarization.
Many teams I advise actually combine both: PMC-LLaMA for evidence retrieval + summarization, Clinical Camel as the chat interface layer on top of curated outputs.
Deployment Tutorial: How to Run These Medical LLMs
Licensing & Commercial Use: What You Need to Know
Both model families inherit Meta LLaMA-style licenses plus project-specific terms:
- Many checkpoints are research-only: some allow commercial use with restrictions.
- You should review the exact license on:
If you’re in a regulated environment, get legal sign-off on licenses before integrating into any paid product.
Step-by-Step Setup Guide: Python & Hardware Requirements
For a typical GPU server (A100 40–80 GB or 2×24 GB cards):
- Create env
python -m venv venv && source venv/bin/activate
pip install --upgrade pip transformers accelerate bitsandbytes sentencepiece- Authenticate with Hugging Face (for gated LLaMA weights).
- Load model (example for 13B PMC-LLaMA):
- In your script, use
AutoModelForCausalLM.from_pretrained("axiong/PMC_LLaMA_13B", device_map="auto", load_in_8bit=True).
- In your script, use
- Add chat wrapper: carry out a simple chat loop that maintains conversation history and enforces max tokens.
- Clinical Camel: similar steps, but for 70B you’ll likely need 2–4 high-memory GPUs or quantization (e.g., 4-bit with bitsandbytes or GGUF for llama.cpp/llama.cpp-based servers).
For HIPAA/GDPR, I recommend on-prem or VPC deployment only, with audited logs and PHI redaction at the application layer.
Real-World Applications: Implementing Medical AI
Deploying Clinical Chatbots for Patient Triage & Interaction
In one internal experiment, I used Clinical Camel as the NLU core of a triage assistant that:
- collected symptoms and timeline,
- mapped them to urgency buckets,
- generated a clinician-facing summary in SBAR format.
We hard-coded rules for red flags (e.g., suspected stroke, ACS). If they triggered, the system overrode the model and instructed urgent evaluation regardless of what the LLM suggested. That kind of rule overlay is non-negotiable in production.
Next-Gen Educational Tools for Medical Training
For resident and student education, PMC-LLaMA is particularly useful to:
- generate case-based discussion prompts grounded in recent literature,
- summarize new trials for morning report handouts,
- draft explanations at different difficulty levels (MS3 vs PGY-3).
I’ve had good results combining:
- PMC-LLaMA to draft evidence-based content.
- Clinical Camel to rephrase it into patient-friendly or learner-friendly language.
Every piece is still reviewed by a human educator before release, but the time-to-first-draft drops dramatically.
Safety First: Limitations, Hallucinations, and HIPAA Considerations
Both Clinical Camel and PMC-LLaMA are research models, not FDA-cleared medical devices (as of late 2025 to my knowledge).
Key risks:
- Hallucinations: fabricated guidelines, incorrect dosing, non-existent trials.
- Out-of-date content: training data lags behind current standards of care.
- Bias: under-representation of certain populations in source literature.
Risk-mitigation strategies I insist on:
- Keep them behind the firewall, with no PHI leaving your controlled environment.
- Use RAG with versioned guidelines (e.g., 2022 AHA, 2021 GOLD) and force the model to answer only from retrieved passages.
- Add hard constraints for high-risk domains (dosing, chemo regimens, pediatrics). Prefer lookups from structured drug databases instead.
- Maintain an explicit policy: outputs are drafts for clinicians, not orders.
Medical Disclaimer
Nothing in this text is medical advice. These models must not be used to diagnose, treat, or manage real patients without licensed clinicians, proper validation, and regulatory clearance. In emergencies, patients should always seek immediate in-person care.
Conclusion: Selecting the Ideal Medical LLM for Your Project
If I had to oversimplify:
- Choose Clinical Camel when you need a conversation-first clinical assistant prototype.
- Choose PMC-LLaMA when you need a literature-native engine for evidence synthesis and education.
For most serious deployments, I recommend a hybrid stack: PMC-LLaMA for evidence extraction and summarization, Clinical Camel (or similar dialogue-tuned models) as the interaction layer, all wrapped in RAG, safety rules, and human oversight.
Frequently Asked Questions
What is the main difference between Clinical Camel and PMC-LLaMA?
Clinical Camel is an instruction-tuned, dialogue-focused medical LLM optimized for clinical conversations, triage-style questioning, and resident teaching. PMC-LLaMA is trained on ~4.8M PubMed Central papers, making it stronger for literature-grounded summarization, evidence synthesis, and extracting endpoints or study details from dense academic texts.
When should I choose Clinical Camel vs PMC-LLaMA for a hospital or MedTech project?
Use Clinical Camel when you need a conversation-first clinical assistant, such as internal Q&A, triage-style chat, or clinician messaging. Choose PMC-LLaMA when your primary need is evidence synthesis, abstract summarization, or research support. Many teams combine both: PMC-LLaMA for retrieval/summaries and Clinical Camel as the chat layer.
Is it safe to use Clinical Camel or PMC-LLaMA for real patient triage or clinical decisions?
No. Both are research models and not FDA-cleared medical devices. They can hallucinate, be out-of-date, and show bias. They should only support clinicians with guardrails: RAG over current guidelines, rule-based overrides for high-risk situations, strict on-prem deployment, and mandatory human review of every clinically relevant output.
How can I deploy Clinical Camel vs PMC-LLaMA under HIPAA or GDPR constraints?
Deploy on-prem or in a tightly controlled VPC, never as a public SaaS endpoint. Use audited logging, PHI redaction at the application layer, and access controls. Load the models via Hugging Face with quantization if needed, and layer RAG plus safety rules on top before exposing outputs to clinicians.
Which model is better for USMLE or medical education use cases?
PMC-LLaMA generally performs better on USMLE-style questions and literature-based explanations, thanks to its PubMed Central training. For teaching, many teams use PMC-LLaMA to generate evidence-grounded vignettes and explanations, then pass drafts through Clinical Camel (or similar chat models) to rephrase content for different learner levels or patient-friendly language.
Past Review:





