
A deep dive into the capabilities, implementation pathways, and critical considerations for leveraging Google’s open-source medical AI models.
The intersection of artificial intelligence and medicine is rapidly moving from promise to practice, largely driven by the advent of powerful, domain-specific foundation models. At the forefront of this movement is MedGemma, a family of open-source models from Google designed to interpret complex medical images and text with a high degree of proficiency. Built upon the efficient architecture of Gemma 3, MedGemma is engineered to accelerate research and development in healthcare AI.
This guide provides a comprehensive overview of how to use MedGemma, covering its core components, practical implementation strategies, advanced customization techniques, and the essential ethical considerations for responsible development.
Table of Contents
Understanding the MedGemma Ecosystem
Before diving into implementation, it’s crucial to understand the components that make up the MedGemma collection. These models are not a one-size-fits-all solution but a suite of tools tailored for different needs in terms of modality, performance, and computational resources.
Core Capabilities and Model Variants
MedGemma is a specialized Vision-Language Model (VLM) designed to understand the unique language and visuals of the medical world. Its capabilities span medical text comprehension, clinical reasoning, and image interpretation across various modalities like radiology, pathology, and dermatology. The collection is part of Google’s Health AI Developer Foundations (HAI-DEF), which provides robust starting points for health research and application development.
The MedGemma family includes several key variants:
| Model Variant | Parameters | Modality | Description & Recommended Use |
|---|---|---|---|
| MedGemma 4B | 4 Billion | Multimodal (Image & Text) | A balanced model offering high performance with resource efficiency. It’s the recommended workhorse for many image analysis use cases. It comes in an instruction-tuned (-it) version for general use and a pre-trained (-pt) version for advanced research. |
| MedGemma 27B Text-Only | 27 Billion | Text-Only | Optimized exclusively for medical text comprehension, this model excels at tasks like summarizing Electronic Health Records (EHRs), querying medical literature, and analyzing clinical notes. |
| MedGemma 27B Multimodal | 27 Billion | Multimodal (Image & Text) | A newer, more powerful model that adds support for complex multimodal tasks and interpretation of longitudinal EHR data. |
| MedSigLIP | 400 Million | Vision Encoder | The vision engine powering MedGemma’;s image understanding. It can be used as a standalone encoder for tasks like zero-shot image classification and semantic image retrieval from large medical databases. |
Performance Insights
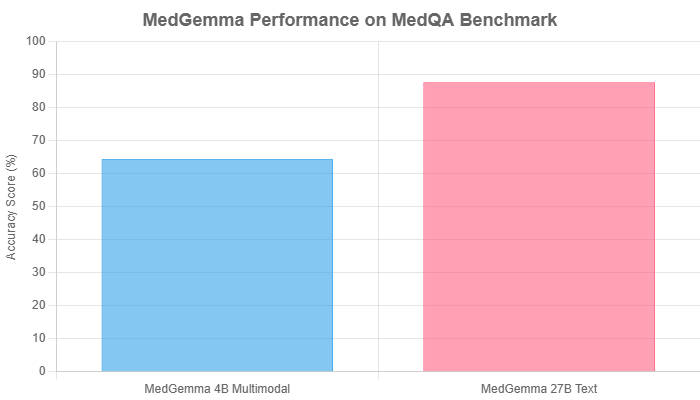
MedGemma models have demonstrated highly competitive performance on challenging medical benchmarks. The larger 27B text model, for instance, achieves an impressive 87.7% score on the MedQA benchmark, a standardized test for medical knowledge. The more resource-efficient 4B multimodal model also holds its own, scoring 64.4% on the same benchmark, ranking it among the best in its size class (<8B parameters).
This performance differential highlights the trade-off between model size and task-specific accuracy, allowing developers to choose the right tool for their needs.
Getting Started: Practical Implementation Pathways
Google provides four primary pathways for developers to start working with MedGemma, catering to different needs from initial experimentation to full-scale production deployment. These methods offer flexibility in terms of infrastructure, cost, and control.
Pathway 1: Local Experimentation
This is the recommended starting point for experimenting with the model’s capabilities without needing to manage cloud infrastructure.
- How it works: Download the desired MedGemma model from Hugging Face and run it on a local machine or in a cloud notebook environment like Google Colab.
- Best for: Researchers, students, and developers who want to explore the model’s functionality, test prompting strategies, or work with smaller datasets.
- Note: Running the full 27B model without quantization requires significant computational resources, such as those provided by Colab Enterprise.
Pathway 2: Production Deployment with Vertex AI
For building production-grade applications, deploying MedGemma as a scalable online service is the ideal approach. This ensures low latency and high availability.
- How it works: Deploy MedGemma as a highly available HTTPS endpoint on Google Cloud’s Vertex AI. The easiest way is through the Model Garden, which simplifies the deployment process.
- Best for: Online applications that require real-time responses, such as interactive diagnostic aids, clinical decision support tools, or patient-facing chatbots.
Case Study: Building “Cymbal MedBuddy” on Vertex AI
A practical example demonstrates deploying medgemma-4b-it on Vertex AI to power a medical image analysis application. The process involves:
- Deploying the Model: Using the Google Cloud CLI to deploy the model from the Model Garden to a dedicated Vertex AI endpoint.
- Building the Application: A Python and Streamlit application sends user prompts and images to the deployed endpoint. Key functions handle initializing the connection to Vertex AI and constructing a detailed system prompt to guide the model’s behavior, ensuring high-quality and safe responses.
Pathway 3: Batch Processing for Large Datasets
When dealing with large volumes of data that don’t require real-time processing, a batch workflow is more efficient and cost-effective.
- How it works: Launch a Vertex AI batch prediction job to process a large dataset (e.g., analyzing thousands of medical images or reports overnight).
- Best for: Large-scale research studies, data annotation tasks, or retrospective analysis of medical records.
Advanced Usage: Fine-Tuning for Specialized Tasks
While MedGemma’s base models are powerful, their true potential is unlocked through fine-tuning. By training the model on your own specific medical data, you can significantly optimize its performance for your unique use case.
Research has shown that fine-tuning can lead to substantial improvements, such as reducing errors in EHR information retrieval by 50% and achieving state-of-the-art performance on niche tasks like pneumothorax classification from chest X-rays.
How to Fine-Tune:
- Use Custom Data: Prepare a dataset specific to your domain (e.g., a collection of brain MRI scans with corresponding reports).
- Leverage Open-Source Tools: Google provides sample notebooks demonstrating how to fine-tune MedGemma using popular libraries like Hugging Face Transformers and techniques like QLoRA for memory-efficient training. These resources serve as excellent starting points.
- Step-by-Step Guides: Tutorials are available that walk through the entire process, from setting up the environment and processing data to fine-tuning the model and evaluating its performance on a specific task.
Critical Considerations: Limitations and Ethical Responsibilities
Using a powerful tool like MedGemma in a sensitive domain like healthcare comes with significant responsibilities. It is not a “plug-and-play” solution but a foundational model that requires careful implementation and oversight.
- Foundation, Not Final Product: MedGemma is a starting point for R&D and is not a clinically approved medical device. It does not replace the need for rigorous clinical trials and validation before being used in a live clinical setting.
- Data Bias and Fairness: The models are trained on vast datasets that may contain inherent biases related to gender, ethnicity, or geography. These biases can lead to poor clinical decisions and worsen existing healthcare inequalities. Developers must validate model performance on data representative of their target population.
- Accountability and Liability: A critical and unresolved question is who bears responsibility if an AI-driven recommendation leads to patient harm. This complex legal and ethical issue must be considered during application design.
- Patient Consent and Transparency: Ethical practice demands transparency. Patients should be informed when AI is involved in their care. A lack of clarity can erode trust between patients and healthcare providers.
Conclusion
MedGemma represents a significant step forward in democratizing AI for healthcare. By providing a suite of powerful, open, and adaptable models, it empowers developers and researchers to build the next generation of medical AI tools more efficiently. From local experimentation on a laptop to scalable production services on the cloud, the pathways to using MedGemma are flexible and well-documented.
However, this power must be wielded with caution. The journey from a foundational model to a reliable clinical tool is paved with rigorous validation, a deep understanding of its limitations, and an unwavering commitment to ethical principles. By embracing both the potential and the responsibilities, the developer community can leverage MedGemma to drive meaningful innovation and improve outcomes in healthcare.





