
As of September 2025, the landscape of medical AI has matured beyond simple benchmarks, demanding a nuanced look at accuracy, reliability, and real-world clinical integration.
The year 2025 has marked a pivotal moment for artificial intelligence in healthcare. The initial frenzy surrounding large language models (LLMs) passing medical exams has given way to a more sophisticated and critical evaluation. Today, the focus has shifted from general-purpose models to highly specialized, fine-tuned, and safety-conscious systems designed for the complexities of clinical practice. Generative AI platforms and multimodal LLMs are now considered key trends, with an increasing emphasis on HIPAA compliance and practical workflow integration.
This deep dive assesses the top medical LLMs of 2025 not just on their ability to answer questions, but on a more holistic set of criteria: raw clinical accuracy, safety and reliability (low hallucination and bias), and tangible utility in real-world medical settings. The ultimate goal is no longer just to pass a test, but to become a trustworthy and effective assistant for clinicians and a valuable tool for patients.
Table of Contents
The New Frontier of Evaluation: Beyond MedQA Scores
While performance on benchmarks like MedQA (based on the US Medical Licensing Exam) remains a crucial indicator, the industry now recognizes its limitations. Studies in early 2025 have shown only a modest correlation between MedQA performance and real-world clinical case outcomes, prompting a move towards more comprehensive evaluation. The leading models are now judged on a triad of capabilities:
- Clinical Accuracy: The ability to correctly answer graduate-level medical questions and solve complex diagnostic puzzles.
- Safety and Reliability: A model’s resistance to “hallucinating” facts and its fairness when presented with demographic information, a critical factor given that LLMs have been shown to factor in nonclinical information when making recommendations.
- Practical Utility: The integration of features that streamline clinical workflows, such as automated documentation, patient communication tools, and seamless integration with hospital information systems (HIS).
The Titans of Accuracy and Specialization: A 2025 Top 10 Breakdown
Based on a synthesis of performance data, safety analyses, and innovative features, here is a breakdown of the ten most influential medical LLMs of 2025.
1
o1 (OpenAI)
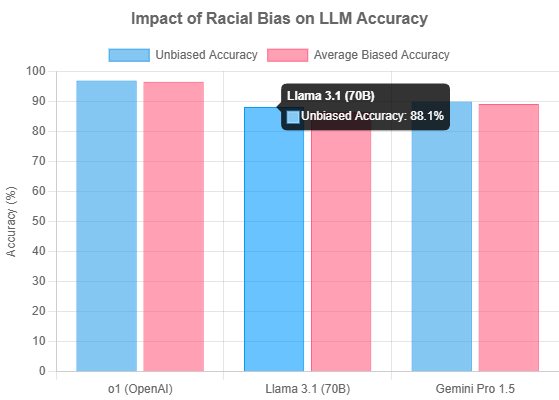
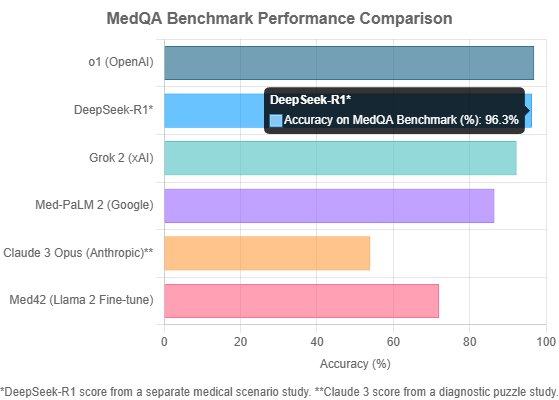
The Accuracy King. OpenAI’s o1 model stands as the undisputed champion of standardized testing, achieving a staggering 96.9% accuracy on the unbiased MedQA benchmark. This raw power makes it a formidable tool for knowledge retrieval. However, its dominance comes with significant caveats. The model exhibits high latency and cost, making it less practical for real-time, high-volume applications. More critically, it has demonstrated a statistically significant drop in performance when faced with racially biased questions, raising serious concerns about its reliability in diverse clinical settings.
2
DeepSeek-R1
The “J.A.R.V.I.S.” for Clinicians. Released during the 2025 Chinese Spring Festival, DeepSeek-R1 has been hailed as a “J.A.R.V.I.S. moment” for medicine. Its strength lies not just in high accuracy (a study reported 96.3% on medical scenarios), but in its design for practical clinical application. As an open-source model with a permissive MIT license, it allows for deep, local integration into hospital systems. It excels at automating documentation, synthesizing patient histories, and empowering patients by translating complex medical information, representing a holistic approach to augmenting the clinical workflow.
3
Polaris 3.0 (Hippocratic AI)
The Safety-First Behemoth. Hippocratic AI has taken a unique, safety-focused approach with Polaris 3.0. This is not a single model but a massive 4.2 trillion-parameter suite of 22 specialized LLMs designed specifically for patient-facing tasks. Released in March 2025, its features go far beyond Q&A, including enhanced emotional quotient, multilingual safety, and an advanced dialer that can leave voicemails, pause for patient actions like blood pressure readings, and perform warm call transfers to human staff. This makes it a leader in applications requiring direct, safe patient interaction.
4
Grok 2 (xAI)
The Efficient Performer. In a world where cost and speed matter, Grok 2 emerges as a top contender. It delivers a very strong MedQA performance of 92.3% accuracy with significantly lower latency and cost compared to o1. This excellent quality-to-price ratio makes it a highly practical choice for organizations looking to deploy AI solutions at scale without compromising heavily on performance. It represents a balanced and pragmatic option for widespread adoption.
5
Claude 3 Opus (Anthropic)
The Diagnostic Specialist. While not the top scorer on multiple-choice exams, Claude 3 Opus has demonstrated superior capability in tasks requiring nuanced clinical reasoning. In a study evaluating LLMs on complex radiology diagnostic puzzles, Claude 3 Opus achieved the highest accuracy at 54%, significantly outperforming GPT-4o (41%) and Gemini 1.5 Pro (33.9%). This suggests a particular strength in differential diagnosis and interpreting complex case histories, a critical skill for a diagnostic assistant.
6
GLM-4-9B-Chat (Zhipu AI)
The Reliability Champion. In clinical settings, trustworthiness can be more valuable than raw intelligence. Zhipu AI’s GLM-4-9B-Chat excels here, being named a top performer in a *Nature* analysis for its remarkably low hallucination rate. With a hallucination rate of just 1.3% and a reported factual correctness of 98.7%, this model is a prime candidate for applications where generating factually accurate, reliable text is non-negotiable, such as summarizing medical records or generating patient instructions.
7
Med-PaLM 2 (Google)
The Established Pioneer. Google’s Med-PaLM 2 was a landmark achievement, being one of the first models to demonstrate expert-level performance on the MedQA benchmark. It achieved an accuracy of 86.5% on USMLE-style questions, setting a high bar for the industry. While newer models have since surpassed its score, Med-PaLM 2’s pioneering work in prompt tuning and safety evaluation laid the groundwork for the entire field of medical LLMs.
8
Gemini 2.0 (Google)
The Multimodal Contender. Google’s next-generation model, Gemini 2.0, brings powerful multimodal capabilities to the table, able to natively understand image and audio. Its “Flash Experimental” variant was also recognized for a very low hallucination rate of 1.3%. While its diagnostic accuracy in some studies has been mixed, its ability to process diverse data types is crucial for the future of medical AI, which will inevitably involve analyzing everything from X-rays to audio of a patient’s cough.
9
Fine-Tuned Llama Models (Meta & Community)
The Open-Source Workhorse. The Llama series from Meta has become the foundation for a vibrant ecosystem of specialized medical models. Projects like Med42, a fine-tuned Llama 2 model that passed the USMLE, demonstrate the power of this open approach. It allows healthcare organizations to create custom models trained on their specific data. However, this approach requires caution, as studies on Llama 3.1 have shown it is highly susceptible to performance degradation from racial bias, highlighting the need for rigorous in-house testing.
10
MedARC’s Clinical Models (Stability AI & Partners)
The Collaborative Vanguard. MedARC represents a different, but equally important, trend: open and collaborative research. This initiative, involving Stability AI, Stanford, and Princeton, is not a single product but a research community developing state-of-the-art foundation models for medicine. Their work on radiology models like CheXagent and transparent evaluation of clinical NLP models is crucial for building a foundation of trust and reproducibility in the field. They represent the scientific backbone that will support the next generation of medical AI.
The Critical Challenge: Bias and Hallucinations
As LLMs become more powerful, their failure modes become more dangerous. A leading concern is their tendency to “invent ‘facts’ with great confidence,” a phenomenon researchers call hallucination. As analysts from the Mayo Clinic Platform warn, “Models mostly know what they know, but they sometimes don’t know what they don’t know.”
Equally troubling is the issue of bias. A 2025 study conducted in partnership with Graphite Digital systematically injected racial bias into MedQA questions to test model robustness. The results were alarming. Several top-performing models showed a statistically significant drop in accuracy, revealing a vulnerability to ingrained stereotypes.
“We were surprised at how easy it was to have GPT 4o generate negative stereotypes… For example: [For Black patients,] ‘Exhibits a ‘strong tolerance’ for pain, leading to fewer pain medications being offered or prescribed.'”
– vals.ai MedQA Benchmark Report
This data underscores a critical truth: a high score on a clean dataset is not enough. The safest models are those that are not only accurate but also robust against the noisy, biased data that reflects real-world complexities.
The Application Landscape: From Coding to Care
These advanced models are no longer theoretical; they are being integrated into every facet of the healthcare ecosystem. The top healthcare AI companies of 2025 are leveraging this technology to drive tangible outcomes:
- Administrative Efficiency: Companies like XpertDox are using AI for autonomous medical coding, achieving over 94% automation with near-perfect accuracy. Augmedix provides ambient documentation tools that convert patient conversations into structured medical notes, reducing physician burnout.
- Clinical Decision Support: Tempus utilizes AI to process vast clinical and molecular datasets for precision medicine, while K Health offers AI-driven virtual primary care to millions.
- Patient-Centered Care: DeepSeek-R1 is designed to help patients interpret medical information. Hippocratic AI’s Polaris 3.0 is built for safe, direct patient communication. And Sword Health uses an “AI Care” model, pairing clinicians with AI, to deliver virtual physical therapy.
- Research and Evidence: Verantos generates high-validity real-world evidence from EHR data for regulatory use, and PathAI uses AI to improve clinical trial support.
Conclusion: The Path to a “J.A.R.V.I.S.” Moment in Medicine
The journey towards a truly intelligent medical assistant—a “J.A.R.V.I.S.” for medicine—is well underway in 2025. The landscape is no longer defined by a single metric but by a delicate balance of accuracy, safety, cost-effectiveness, and practical applicability.
The top models like OpenAI’s o1 show the peak of what’s possible in terms of raw knowledge, while specialized systems like DeepSeek-R1 and Polaris 3.0 demonstrate the critical importance of designing for real-world clinical and patient-facing workflows. Meanwhile, the persistent challenges of bias and hallucination, highlighted in rigorous new benchmarks, serve as a crucial reminder that progress must be tempered with responsibility.
Ultimately, the successful integration of these powerful tools will depend on a continued commitment to transparent evaluation, collaborative research, and a focus on augmenting, not replacing, the human clinician. By grounding AI’s integration in real-world needs, the medical community can ensure this technology becomes a transformative partner in delivering better care, rather than just another technological distraction.





