
The integration of Large Language Models (LLMs) into specialized fields like medicine holds immense promise, but it also presents unique challenges regarding accuracy, reliability, and accessibility. In this context, BioMistral 7B has emerged as a significant open-source contender. Developed by further pre-training the Mistral 7B model on a vast corpus of biomedical literature from PubMed Central, BioMistral aims to provide a powerful, lightweight, and transparent alternative to proprietary models. This article provides a deep dive into its performance across various medical benchmarks, drawing on extensive research and comparative data.
Table of Contents
The Genesis of BioMistral 7B: Bridging a Gap in Medical AI
The development of BioMistral was motivated by a critical need within the healthcare AI community. While powerful proprietary models like GPT-4 and Med-PaLM 2 demonstrated impressive capabilities, their closed-source nature raised concerns about data privacy, cost, and reproducibility. This created a demand for open-source, commercially viable models that could be fine-tuned and deployed on consumer-grade hardware. BioMistral was designed to fill this gap by building upon the efficient and high-performing Mistral 7B architecture.
The project’s contributions are multifaceted, including the release of the base BioMistral 7B model, an analysis of different evaluation strategies, and the creation of a multilingual medical benchmark to test generalization. Furthermore, the researchers explored novel model merging techniques, resulting in variants like BioMistral 7B DARE, TIES, and SLERP, which combine the specialized knowledge of BioMistral with the general reasoning abilities of its foundation model, Mistral 7B Instruct. These models and their associated resources are freely available under an Apache 2.0 license, fostering further research and development.
Performance on Core Medical QA Benchmarks
The primary evaluation of BioMistral 7B was conducted on a comprehensive benchmark of 10 established medical question-answering (QA) tasks in English, including well-known datasets like MedQA, PubMedQA, and MedMCQA. The model’s performance was assessed using two distinct methods: Supervised Fine-Tuning (SFT) and few-shot learning.
Supervised Fine-Tuning (SFT) Evaluation: A Clear Performance Leap
Supervised Fine-Tuning proved to be a critical step in unlocking BioMistral’s full potential. The SFT process led to significant performance improvements across nearly all datasets, establishing BioMistral 7B as a top performer among open-source medical models in its weight class. On average, BioMistral 7B outperformed its base model, Mistral 7B Instruct, on 7 out of the 10 tasks, demonstrating the tangible benefits of domain-specific training.
When compared to other 7B medical models, the advantage is even more pronounced. As the chart below illustrates, BioMistral 7B’s average accuracy of 57.3% across the 10 tasks is substantially higher than that of MedAlpaca 7B (51.5%) and MediTron-7B (42.7%). This highlights its superior ability to handle complex medical reasoning after specialized fine-tuning.
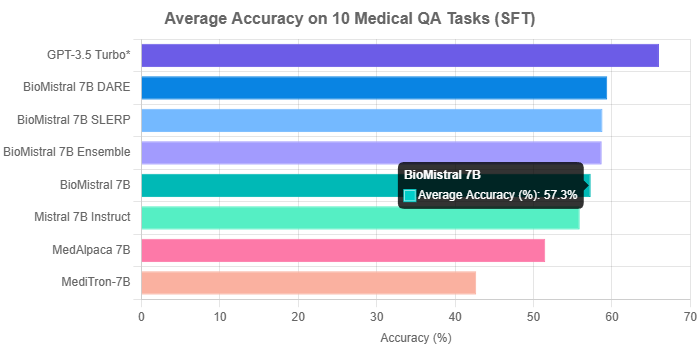
Average accuracy of various 7B models and GPT-3.5 Turbo on a 10-task medical QA benchmark after Supervised Fine-Tuning. Data sourced from the BioMistral 7B Hugging Face model card.
Few-Shot Learning Insights: Strengths and Weaknesses
In a 3-shot in-context learning scenario (where the model is given three examples before answering), BioMistral 7B also demonstrated strong performance. It surpassed all other open-source biomedical baselines on all tasks in this setting, with notable gains over models like MedAlpaca 7B and MediTron-7B on MedQA and MedMCQA. For instance, it showed a 9.0% and 7.0% increase over MedAlpaca 7B on the MedQA 4 and 5-option tasks, respectively.
However, this evaluation also revealed a key weakness. In the few-shot setting, BioMistral’s performance on the PubMedQA dataset saw a significant decline, with accuracy dropping at least 15.7% lower than other models. The researchers attributed this to hallucinations caused by imbalanced classes in the dataset. This issue was later rectified through the SFT process, where its PubMedQA score rose dramatically to 77.5%, underscoring the importance of robust fine-tuning to overcome initial model biases.
Comparative Analysis and Model Variants
A deeper look at the benchmark results reveals nuanced differences between BioMistral, its general-purpose predecessor, and its own specialized variants.
BioMistral vs. General-Purpose Models
The direct comparison between BioMistral 7B and Mistral 7B Instruct is particularly insightful. While BioMistral’s domain training gave it an edge in most medical tasks, Mistral 7B Instruct surprisingly outperformed it on tasks like Clinical KG (62.9 vs 59.9) and College Biology (62.5 vs 59.0). This suggests that for certain subjects, a strong general-purpose model can still be highly competitive. Nonetheless, BioMistral’s overall higher average score confirms the value of its specialized pre-training.
Against proprietary models, the gap remains. GPT-3.5 Turbo, without any specific supervised fine-tuning for this benchmark, achieved an average score of 66.0%, outperforming all BioMistral variants. This highlights that while open-source models are rapidly closing the gap, larger, proprietary models still often maintain a performance advantage.
The Power of Merging: DARE, SLERP, and TIES
Perhaps one of the most innovative aspects of the BioMistral project is the exploration of model merging techniques. Variants like DARE (Dynamic and Random Ensemble), SLERP (Spherical Linear Interpolation), and TIES are created by merging the layers of BioMistral 7B and Mistral 7B Instruct. The goal is to create a single model that retains the specialized medical knowledge of BioMistral while leveraging the broad, common-sense reasoning of Mistral.
The results confirm the success of this approach. The merged variants consistently outperformed the original BioMistral 7B model. As seen in the chart above, BioMistral 7B DARE achieved the highest average accuracy among the family at 59.4%, followed closely by SLERP (58.8%) and Ensemble (58.7%). This demonstrates that combining domain-specific and general-purpose models can lead to a more robust and capable LLM.
Performance on Broader Clinical Benchmarks: The ClinicBench Evaluation
To assess performance beyond standard QA, BioMistral was also evaluated on ClinicBench, a comprehensive benchmark designed to test LLMs on more realistic clinical scenarios. ClinicBench includes 11 tasks across reasoning, generation, and understanding, such as treatment recommendation, patient education, and hospital summarization.
In this extensive evaluation involving 22 different LLMs, BioMistral 7B again proved its mettle. It achieved a PubMedQA score of 77.0% and a MMLU-Med score of 52.6%. Across the board, it consistently surpassed other 7B-parameter medical models like MedAlpaca-7B and Meditron-7B, reinforcing its position as a leading open-source model for diverse clinical language tasks.
Contextualizing Performance and Acknowledged Limitations
While BioMistral’s performance is impressive, it is essential to place it within the rapidly evolving landscape of medical AI and to acknowledge its limitations.
The State-of-the-Art Context
The field of medical LLMs is advancing at a breakneck pace. Shortly after BioMistral’s release, other models have claimed new state-of-the-art results. For example, John Snow Labs announced a 7B model that achieved 78.4% accuracy on PubMedQA, slightly edging out BioMistral DARE’s 77.7% and BioMistral SLERP’s 77.8%. This illustrates the competitive nature of the field and shows that performance leadership can be transient.
Furthermore, some research suggests that the advantage of domain-specific adaptation is not always absolute. One study found that BioMistral-7B underperformed compared to a newer version of its base model, Mistral-7B-Instruct-v0.2, indicating that improvements in general-purpose foundation models can sometimes outpace the benefits of specialized training.
Crucial Cautions and Responsible Use
The creators of BioMistral are explicit about the model’;s limitations and issue strong warnings against its premature use in clinical practice. They state:
This advisory underscores that despite its strong benchmark performance, the model has not been evaluated in real-world clinical settings or undergone the rigorous testing, including randomized controlled trials, necessary for safe deployment. It should be treated strictly as a research tool.
Conclusion
BioMistral 7B and its variants represent a landmark achievement in the development of open-source medical AI. Through specialized pre-training on high-quality biomedical data and innovative model merging techniques, it has set a new standard for 7-billion-parameter models, demonstrating performance superior to many of its open-source peers across a wide range of medical reasoning tasks.
Its success, particularly that of the DARE and SLERP merged variants, highlights a promising path forward: combining deep domain knowledge with broad general intelligence. However, its performance relative to top-tier proprietary models and the rapid pace of innovation in the field serve as a reminder that the journey is far from over. Most importantly, the explicit cautions from its creators reinforce a critical message: while benchmarks are valuable, the path to responsible, real-world clinical application requires a level of safety, validation, and ethical consideration that extends far beyond academic performance metrics.





