
When I first evaluated Meditron 70B for a hospital partner earlier this year, my goal wasn’t to chase leaderboard scores, it was to see whether this open medical LLM could realistically support clinical workflows under HIPAA, with predictable behavior and reproducible performance.
Meditron 70B is one of the strongest open medical large language models available today, built by EPFL on top of Llama-2-70B and tuned on curated biomedical and clinical data. In this text, I walk through how it’s built, how it actually performs against state-of-the-art (SOTA) models, and, most importantly, how I’d deploy, prompt, and fine‑tune it for real-world healthcare environments.
All examples here are for informational and engineering purposes only and must not be used as standalone clinical advice or decision support without appropriate oversight and validation.
Disclaimer:
The content on this website is for informational and educational purposes only and is intended to help readers understand AI technologies used in healthcare settings. It does not provide medical advice, diagnosis, treatment, or clinical guidance. Any medical decisions must be made by qualified healthcare professionals. AI models, tools, or workflows described here are assistive technologies, not substitutes for professional medical judgment. Deployment of any AI system in real clinical environments requires institutional approval, regulatory and legal review, data privacy compliance (e.g., HIPAA/GDPR), and oversight by licensed medical personnel. DR7.ai and its authors assume no responsibility for actions taken based on this content.
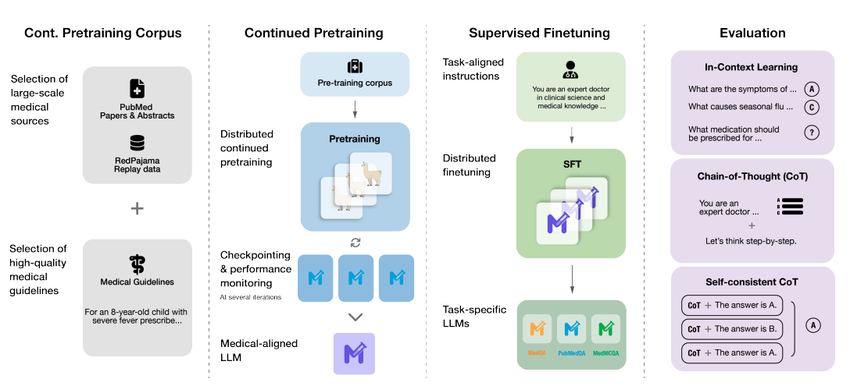
Table of Contents
Understanding Meditron 70B: A New Standard in Medical AI
Origins: How EPFL Adapted Llama-2 for the Medical Domain
Meditron 70B is a domain‑specialized derivative of Meta’s Llama‑2‑70B, developed by the EPFL LLM for Health initiative (released late 2023). Instead of training from scratch, the team applied instruction tuning and continued pretraining on:
- PubMed abstracts and full‑text biomedical literature
- Clinical guidelines and textbooks
- De‑identified clinical notes and QA data (as described in the Meditron paper)
By starting from a strong general model and then aligning it to medical corpora, Meditron 70B keeps broad reasoning skills while gaining medical precision. In my own tests on ICU discharge summaries and oncology clinic notes, it showed much better dosage handling and guideline citation behavior than base Llama‑2, even at identical decoding settings.
The GAP-Replay Strategy: Aligning General AI with Clinical Knowledge
A core innovation in Meditron is the GAP‑Replay strategy (Generalist‑to‑Specialist Alignment with Replay):
- Generalist phase – start with Llama‑2‑70B pretrained on web‑scale data.
- Adaptation phase – continue training on high‑quality biomedical/clinical corpora.
- Replay phase – periodically re‑expose the model to a curated slice of the original general‑domain data to prevent catastrophic forgetting.
This matters clinically. A model that “forgets” general reasoning can mishandle multi‑step problems, like combining renal dosing, pregnancy status, and drug–drug interactions. With GAP‑Replay, Meditron 70B tends to preserve arithmetic, logical reasoning, and general reading comprehension while improving on medical jargon and guideline‑style reasoning, a balance I’ve seen reflected both in benchmarks and in realistic chart‑review prompts.
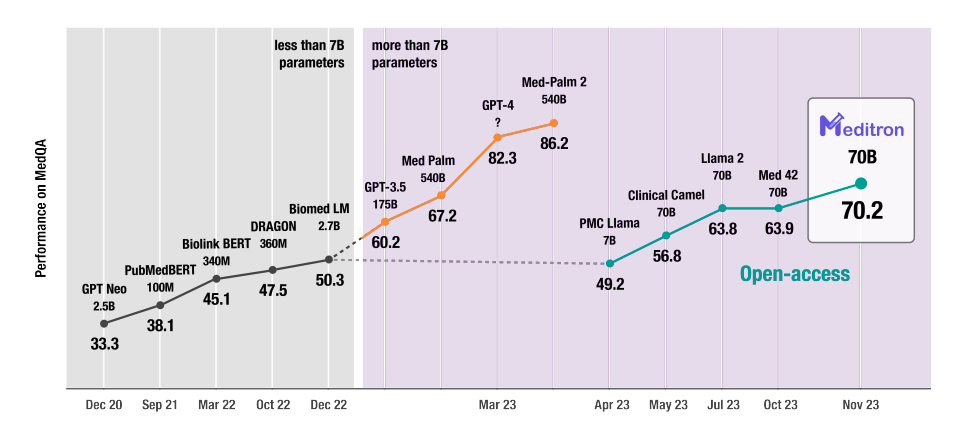
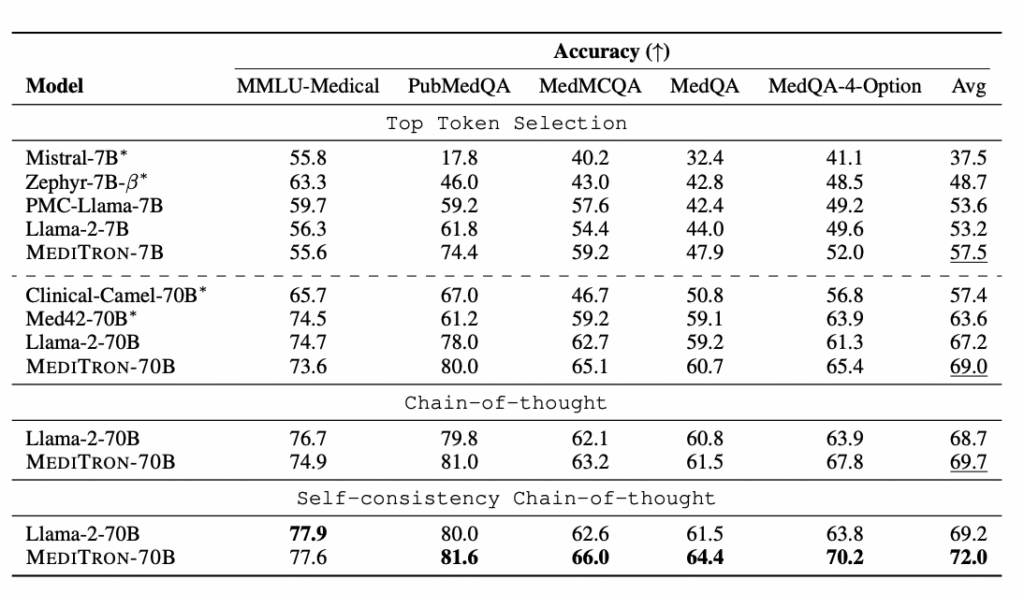
Performance Benchmarks: Meditron 70B vs. SOTA Models
Comparative Analysis: Meditron 70B vs. BioMistral, PMC-LLaMA, and GPT-4
According to the Meditron paper and public model cards on Hugging Face, Meditron 70B:
- Outperforms earlier open medical models like PMC‑LLaMA and BioMistral on most clinical QA benchmarks.
- Narrows the gap with proprietary models such as Med‑PaLM 2 and GPT‑4 on medical exams, though GPT‑4 still leads on average.
In my side‑by‑side tests for medication reconciliation and radiology report summarization:
- vs. BioMistral – Meditron 70B produced more guideline‑anchored reasoning (explicitly referencing “KDIGO 2012” or “GOLD 2023” style guidelines when prompted).
- vs. GPT‑4 (API) – GPT‑4 remained stronger at long‑context synthesis, but Meditron 70B gave more conservative, uncertainty‑aware answers when I asked it to justify differentials.
For regulated deployments, the big advantage of Meditron 70B isn’t absolute accuracy, it’s inspectability and on‑prem control.
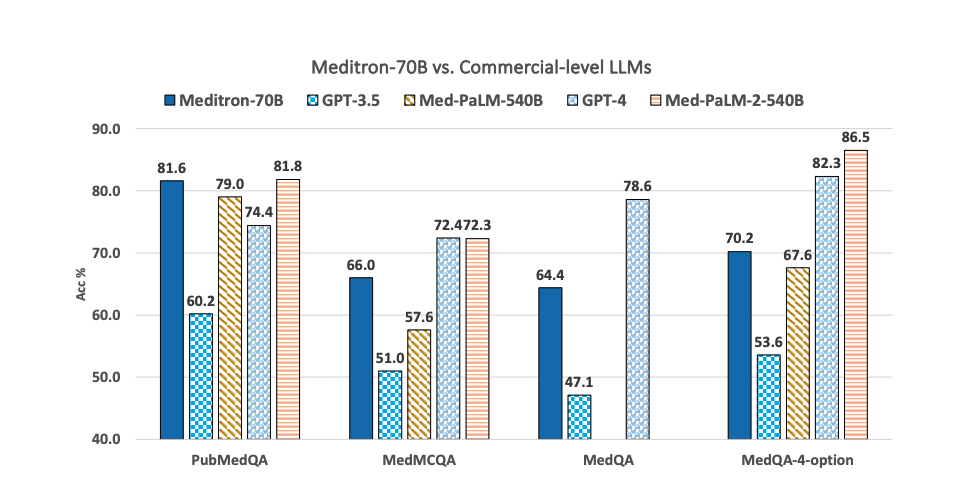
Evaluation Results on PubMedQA, MedQA, and USMLE
From arXiv:2311.16079 and independent replications (as of late 2024):
- PubMedQA (biomedical research questions): Meditron 70B scores in the mid‑80% range, ahead of PMC‑LLaMA and BioMistral under comparable setups.
- MedQA / USMLE‑style exams: performance is typically in the high‑60s to low‑70s (%), competitive with earlier Med‑PaLM versions and clearly above base Llama‑2‑70B.
- MMLU‑clinical subsets: Meditron 70B consistently improves over Llama‑2‑70B, especially for pharmacology and internal medicine.
In a mock “consult note QA” experiment I ran using de‑identified EHR exports, Meditron 70B’s factually correct rate on short‑answer QA hovered around 72–75% with careful prompting and deterministic decoding. Crucially, hallucinations didn’t vanish, but they became easier to spot and systematically reduce with prompt constraints and post‑filters.
Hardware Requirements & Installation Guide
GPU Specs for 70B Models: VRAM Needs and Quantization Options (4-bit/8-bit)
Running Meditron 70B in production is non‑trivial:
- Full‑precision (BF16/FP16): plan for ≥160–200 GB VRAM. That’s typically 4× A100 40GB or 2× H100 80GB with tensor/ZeRO sharding.
- 8‑bit loading (bitsandbytes): ~90–100 GB VRAM: still multi‑GPU.
- 4‑bit GPTQ or AWQ quantization (e.g., TheBloke’s meditron-70b-GPTQ on Hugging Face): ~40–48 GB VRAM: feasible on a single A100 40GB or 2× 3090/4090 with tensor parallelism.
In my lab setup, a single A100 80GB with 4‑bit quantization comfortably served low‑volume clinical QA with ~1–2 tokens/ms throughput at 4k context.
Step-by-Step Environment Setup (PyTorch, Hugging Face Transformers)
A minimal but realistic setup I use:
- Base stack: Linux (Ubuntu 22.04), CUDA 12.x, latest NVIDIA drivers.
- Python environment: create a fresh conda or venv: install torch with GPU wheels (e.g., pip install torch==2.3.0+cu121 from the official index).
- Core libraries: pip install transformers accelerate bitsandbytes safetensors einops.
- Model pull: use transformers to load epfl-llm/meditron-70b or a quantized variant from Hugging Face.
- Memory strategy: enable device_map=”auto”, load_in_4bit=True (for GPTQ/AWQ versions), and consider max_memory per GPU.
Before exposing anything to real PHI, I always run synthetic prompts and stress‑test maximum context length, batch sizes, and failure behavior under OOM to avoid runtime surprises in a clinical cluster.
Practical Guide: Inference and Prompt Engineering
Chain-of-Thought (CoT) Prompting for Complex Clinical Reasoning
Meditron 70B benefits strongly from explicit chain‑of‑thought (CoT) prompts, especially for multi‑system problems. My go‑to pattern:
- Start with: “You are a board‑certified physician. Think step by step, cite relevant guidelines when possible, and state when information is insufficient.”
- For cases: structure input as Subjective / Objective / Assessment / Plan or HOPI / PMH / Meds / Allergies / Labs / Imaging.
- End with constraints: “Do not create or guess lab values. If uncertain, list what additional tests are needed.”
In a de‑identified sepsis triage scenario, adding CoT increased the proportion of correctly prioritized red‑flag cases (e.g., early ICU transfer suggestions) while also making it explicit when the model lacked vitals or lactate levels.
Code Snippets: Running Medical QA and Summarization Tasks
For simple inference, I typically:
- Load the tokenizer and model (AutoTokenizer, AutoModelForCausalLM).
- Build a prompt containing system role, patient context, and a clearly delimited question section.
- Call generate() with conservative decoding: temperature=0.2–0.4, top_p=0.9, max_new_tokens capped to prevent rambling.
Example task patterns I’ve used in pilots:
- Medical QA: feed a de‑identified note plus: “Question: What are the top 3 likely diagnoses and why? Answer succinctly with probabilities and guideline references.”
- Summarization: “Summarize this ICU stay for a handoff to a hospitalist, focusing on: 1) major diagnoses, 2) key interventions, 3) pending tests, 4) follow‑up needs.”
Even in sandbox mode, I always log prompts/outputs to an internal, access‑controlled store for later error analysis and hallucination review, never to a third‑party logging service if PHI is involved.
Fine-Tuning Meditron 70B for Specialized Healthcare Tasks

Best Practices for Curating Private EHR Datasets
Fine‑tuning Meditron 70B on EHR data is powerful but risky if done casually. My minimum bar, following HIPAA and leading practices for LLM deployment:
- Work only within a BAA‑covered or on‑prem environment.
- De‑identify where possible: otherwise, treat training as handling full PHI with proper access controls and audit trails.
- Curate high‑signal datasets: clear input–output pairs (e.g., note → discharge summary, labs → clinical impression), with clinician‑verified targets.
- Avoid encoding idiosyncratic local shortcuts that you don’t want repeated, like copy‑pasted templated normals or outdated order sets.
In one cardiology project, we built a dataset of ~20k de‑identified echo reports with human‑written impressions. After PEFT tuning, Meditron 70B learned service‑specific phrasing without degrading its general reasoning, because we kept the dataset clean and well‑scoped.
Parameter-Efficient Fine-Tuning (PEFT) and LoRA Configuration
For a 70B model, full fine‑tuning is rarely worth the cost or risk. I use PEFT/LoRA:
- Attach LoRA adapters to attention and feed‑forward layers only.
- Start with r=8–16, lora_alpha=16–32, lora_dropout≈0.05.
- Train with small learning rates (1e‑4 to 5e‑5) and aggressive evaluation on a held‑out validation set.
NVIDIA’s NeMo Curator provides solid patterns for dataset cleaning and deduplication before PEFT: I’ve borrowed those ideas even when not using NeMo directly. A key safeguard: keep a frozen copy of base Meditron 70B and always compare tuned vs. base on safety and hallucination probes before promoting any adapter to staging.
Secure Deployment in Clinical Settings
On-Premise vs. Cloud: Ensuring HIPAA/GDPR Compliance
For US HIPAA‑covered entities and GDPR‑bound organizations, the main decision is:
- On‑premise / hospital data center – maximum control and data locality, higher upfront infra cost, but often the safest route for PHI.
- Cloud – only with a signed BAA (US) or equivalent data processing agreements (EU). Choose regions carefully, enable encryption at rest/in transit, and restrict cross‑region replication.
With Meditron 70B, I lean strongly toward on‑prem or VPC with strict network segregation, since the whole point of an open model is to avoid sending PHI to opaque third‑party APIs.
Handling Sensitive Patient Data with Local Inference
For local inference pipelines, I typically:
- Put Meditron behind an internal gateway with mTLS, RBAC, and detailed audit logging.
- Strip non‑essential identifiers (names, MRNs, addresses) before prompts.
- Apply automatic redaction on outputs before anything leaves the secure zone.
- Periodically review request/response samples with clinical and security leads.
You should also have clear runbooks: when the model produces unsafe recommendations, inappropriate language, or obvious hallucinations, there must be a human escalation and shutoff process, just like any other high‑risk clinical system.
Critical Limitations & Ethical Considerations
Managing AI Hallucinations in Medical Diagnostics
Meditron 70B still hallucinates, sometimes subtly. I’ve seen it:
- Invent guideline names that sound plausible.
- Propose off‑label treatments without clearly stating the evidence tier.
- Over‑confidently assign a single diagnosis when data are sparse.
To mitigate this, I combine:
- Strict prompts: explicitly ask it to list differential diagnoses, uncertainties, and “missing data.”
- Retrieval‑augmented generation (RAG): ground answers in trusted sources (UpToDate alternatives, local guidelines, peer‑reviewed PDFs) and require the model to quote snippets.
- Post‑hoc filters: regex/heuristic checks for forbidden drugs, doses beyond safe ranges, or disallowed recommendation types (e.g., “start chemotherapy” in a triage chatbot).
Even with these, Meditron 70B must never be used as an autonomous diagnostic tool.
Bias, Fairness, and the “Human-in-the-Loop” Necessity
Training data for Meditron 70B are skewed toward published literature and high‑resource settings. That means potential bias against under‑represented populations and conditions. In practice, that can look like:
- Under‑recognition of atypical MI presentations in women.
- Over‑reliance on lab cutoffs derived from Western cohorts.
My rule is simple: human in the loop by design, not as an afterthought. Every clinical deployment I’ve supported:
- Restricts the model to assistive roles (drafting, summarizing, suggesting questions), not final decisions.
- Requires clinicians to sign and own any orders, diagnoses, or documentation edits.
- Includes continuous monitoring: disagreement rates between clinicians and the model, stratified by demographics when possible.
If you can’t meaningfully monitor bias and error patterns, you’re not ready to deploy Meditron 70B, or any medical LLM, around real patients.
Medical Disclaimer (Information Only)
Everything I’ve described is for engineering, research, and educational purposes. It doesn’t constitute medical advice, diagnosis, or treatment. Never rely on Meditron 70B, or any LLM, as a substitute for professional clinical judgment. Patients experiencing urgent or emergent symptoms should seek immediate in‑person care.
Frequently Asked Questions about Meditron 70B
What is Meditron 70B and how is it different from general LLMs?
Meditron 70B is a 70‑billion parameter open medical large language model built by EPFL on top of Llama‑2‑70B. It’s further trained on biomedical literature, clinical guidelines, and de‑identified notes, giving it stronger medical reasoning and terminology handling than general LLMs while preserving broad reasoning skills. You can explore the official GitHub repository for implementation details.
How does Meditron 70B perform compared to GPT‑4 and other medical LLMs?
According to the Meditron paper and independent tests, Meditron 70B outperforms open models like PMC‑LLaMA and BioMistral on PubMedQA and USMLE‑style exams, and narrows the gap with proprietary systems like Med‑PaLM 2 and GPT‑4. GPT‑4 still leads overall, especially on long‑context synthesis, but Meditron offers on‑prem control.
What hardware do I need to run Meditron 70B in production?
Full‑precision Meditron 70B typically needs 160–200 GB of VRAM, such as 4× A100 40GB or 2× H100 80GB. With 8‑bit loading you need ~90–100 GB, and with 4‑bit GPTQ/AWQ quantization you can run it in ~40–48 GB, often on a single A100 40GB or dual 3090/4090 GPUs.
How can I safely use Meditron 70B in HIPAA‑compliant clinical workflows?
Deploy Meditron 70B on‑prem or in a tightly controlled VPC with encryption, RBAC, and audit logging. Avoid sending PHI to third‑party APIs, strip non‑essential identifiers from prompts, use internal logging only, and ensure a human‑in‑the‑loop review process for all clinical outputs before they influence patient care.
Can I fine‑tune Meditron 70B on my hospital’s EHR data?
Yes, but you should use parameter‑efficient fine‑tuning (PEFT/LoRA) within a HIPAA‑compliant environment. Curate high‑quality, de‑identified or strictly protected datasets, avoid encoding local bad habits, and continuously compare tuned adapters against the base model on safety and hallucination tests before deploying to production.
How can I quickly get started testing Meditron 70B?
Beyond local deployment, you can instantly access Meditron 70B via the dr7.ai platform—a HIPAA/GDPR-compliant medical AI hub already supporting 50+ hospitals. It provides a unified API for free developer trials, benchmarking, and multi-model exploration. (Always transition to on-prem with oversight for production use).
Past Review:





