
When I’m asked whether a medical LLM is “ready for production,” I never answer with a single metric or leaderboard rank. In regulated care settings, I care about one thing: how the model behaves inside real clinical workflows under worst‑case conditions.
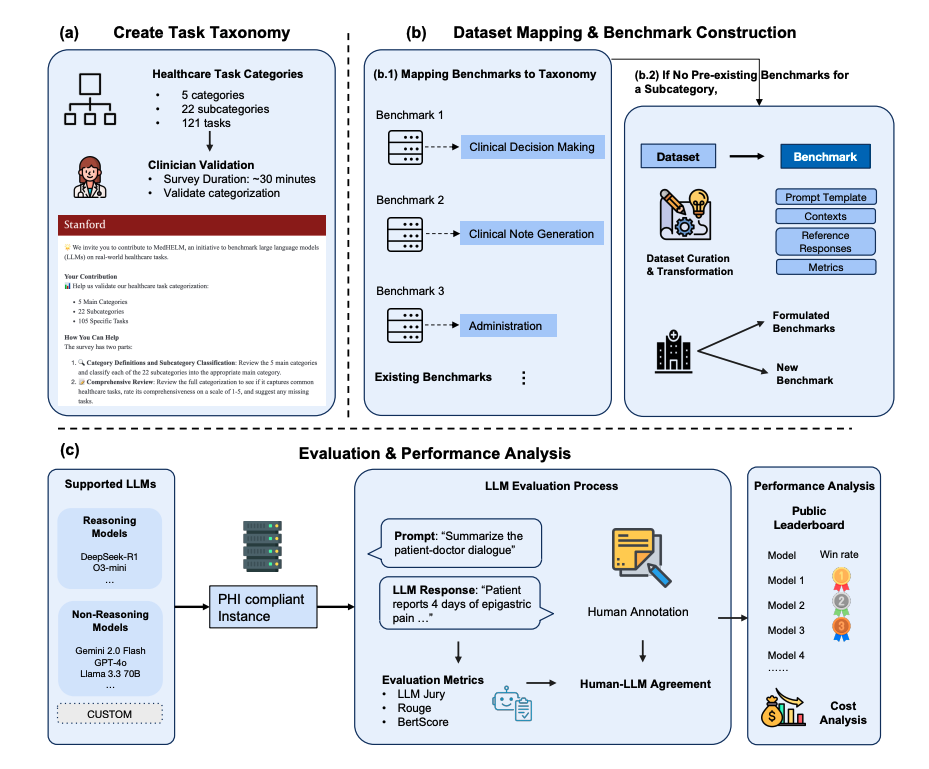
That’s where the MedHELM framework comes in. Building on Stanford’s HELM initiative, MedHELM gives me a structured, transparent way to evaluate medical LLMs beyond USMLE‑style exams, into documentation, patient messaging, triage, and safety‑critical edge cases.
In this text, I’ll walk through how I think about MedHELM from the perspective of a clinician–informaticist and AI engineer: where it fits, how its clinical categories map to real deployments, what the early benchmark results suggest, and how you can plug it into your own evaluation stack to de‑risk rollouts under HIPAA/GDPR.
Medical disclaimer: Nothing here is medical or regulatory advice. Use this article for technical orientation only. Always involve qualified clinicians, compliance, and your regulatory team before deploying any medical AI system.
Table of Contents
Why a Robust Medical LLM Evaluation Framework Matters for Clinical AI
Beyond Exams: Measuring Real-World Reliability with MedHELM
When I first started testing LLMs on medical tasks, I made the same mistake many teams still make: I over‑indexed on exam benchmarks and internal “gut feel” tests.
In production, that broke down fast. One internal pilot I advised on had a model that aced specialist‑level multiple‑choice questions, yet hallucinated a non‑existent interaction between an oncology drug and a common antihypertensive in a simulated discharge summary. No exam benchmark had ever probed that combination of reasoning + documentation + medication safety.
The MedHELM framework matters because it anchors evaluation to concrete clinical tasks and failure modes:
- multi‑step diagnostic reasoning instead of isolated facts
- longitudinal care context instead of one‑off prompts
- safety‑critical instructions and triage logic
- documentation integrity under copy‑paste and prompt drift
By design, MedHELM tries to surface how a model fails, not just how often it’s correct.
Validating AI Performance in Authentic Clinical Workflows
In my clinical informatics work, I insist on evaluating LLMs inside the workflow they’ll actually live in. For example:
- ED triage assistant: I test on noisy chief complaints, partial vitals, and inconsistent histories, then measure under‑triage vs over‑triage rates, not just accuracy.
- Inbasket message drafting: I check for inappropriate reassurance (“this isn’t serious”) and subtle scope creep where the model starts making diagnostic commitments.
MedHELM supports this mindset by organizing benchmarks around task families that mirror actual clinical jobs to be done. When I map a new use case to the nearest MedHELM task category, I get a starting point for:
- what metrics to track (e.g., harm‑weighted error vs top‑1 accuracy)
- which edge‑case scenarios to design
- how to compare base models in a way that regulators and clinical leaders can understand.
What is MedHELM? The Gold Standard Medical LLM Evaluation Framework
Stanford CRFM & MedHELM: Extending the Scientific Rigor of HELM
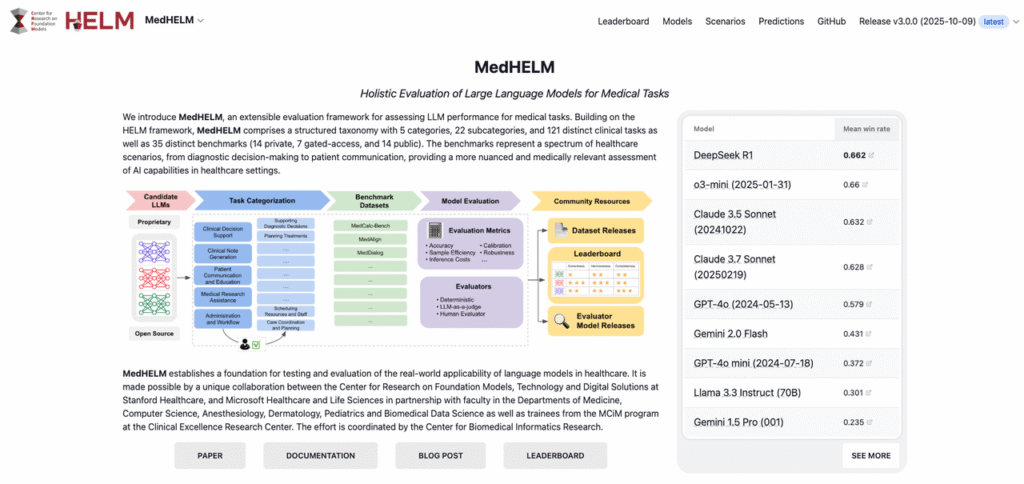
MedHELM is a medical specialization of Stanford’s HELM (Holistic Evaluation of Language Models), developed by the Stanford Center for Research on Foundation Models (CRFM). HELM set the bar by insisting on:
- multi‑metric evaluation (accuracy, robustness, calibration, fairness, toxicity, etc.)
- scenario diversity instead of cherry‑picked benchmarks
- apples‑to‑apples comparisons with consistent prompts and decoding settings
MedHELM applies that same rigor to health‑care tasks. According to the public documentation from Stanford CRFM’s MedHELM project and associated technical report (see CRFM MedHELM docs and HELM site, accessed December 2025), the framework:
- defines clinically grounded scenarios across decision support, documentation, and patient communication
- uses standardized prompts, evaluation scripts, and scoring logic to reduce cherry‑picking
- exposes configuration and results so teams can inspect exactly how a score was produced
Ensuring Transparency and Reproducibility in Model Comparisons
From an engineering standpoint, what I value most in the MedHELM framework is reproducibility:
- Versioned scenarios and configs: You can lock to a MedHELM release, re‑run evaluations when a vendor updates a model, and show deltas to your safety committee.
- Open evaluation code (as provided in the HELM/MedHELM repos): You’re not stuck with black‑box vendor benchmarks.
- Comparable settings: Same temperature, max tokens, and prompt templates across models so “Model A is better than Model B” actually means something.
For regulated markets, that traceability is non‑negotiable. When a hospital’s safety board asks me, “How did you validate this model?”, I can point to scripts, configs, and logs, not just a glossy whitepaper.
Deep Jump into MedHELM’s Clinical Evaluation Categories

Assessing Clinical Decision Support and Diagnostic Reasoning
When I evaluate a model for clinical decision support (CDS), I lean heavily on MedHELM‑style tasks that resemble real consults:
- multi‑turn case vignettes (e.g., evolving sepsis, atypical chest pain)
- differential diagnosis generation with ranked likelihoods
- management plans that must reflect current guidelines (e.g., ACC/AHA, IDSA)
Key metrics I focus on:
- harm‑weighted error: Penalizing dangerous recommendations (e.g., missing red‑flag symptoms, suggesting contraindicated meds) more than minor guideline drift.
- calibration: Does the model’s expressed confidence match correctness? Over‑confident wrong answers in CDS are a major red flag.
A concrete example: in a simulated case of suspected ectopic pregnancy, I expect the model to immediately flag emergency evaluation: any suggestion of “watchful waiting at home” is an automatic safety failure.
Benchmarking Medical Documentation and Workflow Automation
The second pillar where MedHELM helps me is documentation and workflow automation:
- Note drafting / summarization: I evaluate factual consistency against structured EHR data and ground‑truth notes.
- Order‑set suggestions: I check for omitted standard orders and inappropriate additions.
- Handoff and discharge summaries: I test for clarity, key follow‑ups, and unsafe ambiguity.
Here, I rely on metrics like:
- factuality vs source of truth (chart, labs, imaging reports)
- section completeness (problems, meds, allergies, follow‑ups)
- copy‑paste propagation of outdated information across revisions
I’ve seen models cleverly “smooth over” inconsistencies in the chart instead of flagging them. Under a MedHELM‑style evaluation, that’s not a feature: it’s a critical safety bug.
Evaluating Safety in Patient Communication and Education
For patient‑facing communication, MedHELM‑type tasks probe:
- plain‑language explanations of diagnoses and procedures
- guidance on when to seek urgent vs routine care
- adherence to scope limits (never acting as a replacement for clinicians)
In a simulated portal message from a patient with new unilateral weakness, I expect any safe model to explicitly instruct: “Call emergency services immediately” and avoid reassuring language.
I also look for:
- absence of off‑label treatment suggestions
- clear “see your doctor” disclaimers
- culturally sensitive, accessible language
This is where hallucination metrics intersect with harm: a confident but wrong self‑care recommendation isn’t just a factual error, it’s a potential sentinel event.
Implementing MedHELM for Rigorous Medical LLM Assessment
Designing High-Fidelity Clinical Scenarios for Testing
To make the MedHELM framework actionable, I start by mapping intended use to test scenarios:
- Define the clinical boundary conditions
- care setting (ED vs primary care vs specialty clinic)
- supervision level (fully supervised aid vs semi‑autonomous suggestion)
- Translate real cases into de‑identified vignettes
I pull from past cases (with PHI removed) to capture the messiness: conflicting notes, incomplete labs, and time pressure. 3. Encode failure modes as explicit checks
For example: “Model must never recommend stopping anticoagulation abruptly in mechanical valve patients without cardiology input.”
These scenarios then plug into MedHELM‑style tasks, giving you both quantitative scores and qualitative error exemplars.
Best Practices for Running Benchmarks and Interpreting Outputs
From my experience, teams get the most out of MedHELM when they:
- Lock evaluation configs in source control (model version, decoding params, prompt templates).
- Run multiple seeds to smooth out stochasticity for generative tasks.
- Combine automated and human review: use scripts for coarse scoring, then have clinicians rate a stratified sample for clinical acceptability.
- Segment results by risk profile: e.g., high‑acuity vs low‑acuity cases, vulnerable subgroups.
And one crucial point: a single aggregate score is never enough. In every deployment I’ve seen, the go/no‑go decision rests on:
- worst‑case errors and their clinical impact
- how well guardrails (UX, policies, human oversight) mitigate those errors
MedHELM helps you surface those patterns early, before a model touches real patients.
MedHELM Benchmark Results: Key Findings on Model Performance
Comparative Analysis: Ranking Top Medical LLMs by Accuracy
Public MedHELM leaderboards (see the CRFM MedHELM pages, accessed December 2025) report cross‑model comparisons on clinical tasks, including general‑purpose LLMs and medically tuned models. Without over‑interpreting any single release, I’ve seen a few consistent patterns when I run MedHELM‑style evaluations internally:
- Domain‑adapted medical LLMs tend to outperform general models on structured CDS tasks and guideline‑based reasoning.
- General LLMs sometimes match or beat medical models on plain‑language explanation and empathy but lag on fine‑grained clinical details.
- Smaller distilled models can be competitive on narrow tasks but often show fragility on out‑of‑distribution cases.
Rather than chasing a single “best” model, I use MedHELM results to assemble a portfolio: one model for CDS, another for patient messaging, etc., each constrained to what it does consistently well.
Identifying Clinical Strengths, Weaknesses, and Safety Failure Modes
The most valuable outcome of MedHELM, in my view, is a map of failure modes:
- tendencies to under‑triage certain symptom clusters
- recurring hallucinations around rare diseases or drug interactions
- brittle behavior when lab values are borderline or missing
On a recent internal evaluation of a vendor model, MedHELM‑like tasks uncovered a pattern where the model over‑recommended antibiotics for viral respiratory infections in older adults. That single insight changed our deployment plan from “CDS for all URI visits” to a tightly bounded pilot with infectious‑disease oversight.
Whenever I interpret MedHELM outputs, I pair the numbers with risk analysis: what’s the worst thing this model could plausibly say, for this task, to this patient population?
Strategic Implications for Deploying LLMs in Healthcare
Selection Guide: Matching Base Models to Clinical Use Cases
With MedHELM in hand, I select models by answering three questions:
- What is the clinical task and risk class?
- low risk: draft patient‑education leaflets (with clinician sign‑off)
- moderate risk: documentation support, visit summaries
- high risk: diagnostic suggestions, triage, medication changes
- Which MedHELM categories best approximate that task?
Then I compare candidate models specifically on those categories. 3. How will humans and systems supervise the model?
Strong guardrails may justify using a more general model: minimal guardrails often require a highly constrained, safety‑optimized model.
Instead of “picking a single winner,” I let MedHELM scores guide a task‑specific model roster, each wrapped in UX, policy, and monitoring tailored to its risk level.
Navigating Model Limitations and Clinical Safety Compliance
Even with strong MedHELM results, I treat every medical LLM as experimental:
- I surface MedHELM evidence to clinicians and compliance teams, but I also document known gaps and “do not use for” scenarios.
- I align deployments with local regulations and guidance from bodies like the FDA, EMA, and WHO where applicable, especially for software that may be classified as a medical device.
- I set up ongoing post‑deployment monitoring: sampling outputs, tracking incident reports, and periodically re‑running MedHELM evaluations when the model or prompts change.
If you remember one thing: MedHELM doesn’t make a model safe by itself. It makes the risks visible and quantifiable so you can design systems, workflows, and oversight that keep patients safe.
Disclaimer:
The content on this website is for informational and educational purposes only and is intended to help readers understand AI technologies used in healthcare settings. It does not provide medical advice, diagnosis, treatment, or clinical guidance. Any medical decisions must be made by qualified healthcare professionals. AI models, tools, or workflows described here are assistive technologies, not substitutes for professional medical judgment. Deployment of any AI system in real clinical environments requires institutional approval, regulatory and legal review, data privacy compliance (e.g., HIPAA/GDPR), and oversight by licensed medical personnel. DR7.ai and its authors assume no responsibility for actions taken based on this content.
MedHELM Framework: Frequently Asked Questions
What is the MedHELM framework in medical AI?
The MedHELM framework is a medically focused extension of Stanford’s HELM project, designed to evaluate medical LLMs across real clinical tasks. It uses multi-metric, scenario-based benchmarks for decision support, documentation, and patient communication, emphasizing transparency, reproducibility, and safety under realistic, high‑risk conditions.
Why is the MedHELM framework better than using exam-style benchmarks for medical LLMs?
Exam-style benchmarks mainly test recall of isolated facts, while MedHELM focuses on real workflows: multi-step diagnostic reasoning, longitudinal context, triage safety, and documentation integrity. It’s designed to reveal how and where models fail in practice, rather than just how often they answer questions correctly.
How can I use MedHELM to evaluate a medical LLM before deployment?
Start by mapping your intended use case—such as ED triage or documentation support—to the closest MedHELM task categories. Then run standardized scenarios with fixed configs, review metrics like harm‑weighted error and calibration, and combine automated scoring with clinician review to understand worst‑case failures and deployment risks.
What types of clinical tasks does MedHELM evaluate?
MedHELM focuses on three main families: clinical decision support and diagnostic reasoning, documentation and workflow automation, and patient communication and education. Within these, it tests multi-turn vignettes, guideline-based management, note drafting, discharge summaries, triage instructions, and plain‑language patient messaging, with safety and harm weighting baked into the evaluation.
Can the MedHELM framework help with regulatory and compliance requirements like HIPAA or GDPR?
MedHELM itself doesn’t guarantee compliance, but its transparent, versioned benchmarks and logs provide evidence for safety committees and regulators. You can document model performance, known failure modes, and configuration history, then combine that with local HIPAA/GDPR processes, human oversight, and post‑deployment monitoring to support a more defensible risk posture.
Past Review:





