
IMPORTANT DISCLAIMER
This article provides technical information for educational and research purposes only and does not constitute medical, legal, regulatory, or professional advice. Medical AI deployment requires multidisciplinary teams including clinicians, regulatory experts, legal counsel, and ethics committees. Do not deploy any medical AI system based solely on this guidance. Patient safety is paramount – consult qualified professionals and regulatory authorities before any clinical implementation. The authors assume no liability for any outcomes resulting from the use of this information.
If we want to fine-tune a medical AI model that’s safe to deploy under HIPAA/GDPR, we can’t rely on generic recipes. We need curated clinical text, defensible validation, and deployment patterns that survive security reviews. In this playbook, we walk through dataset prep, training, evaluation, and production operations, with an emphasis on benchmarks, hallucination controls, and integration paths that reduce risk in real hospital environments.
⚠️ Critical Safety Note: Medical AI systems that provide patient-specific diagnosis, treatment recommendations, or clinical decision support may be regulated as medical devices and require FDA clearance (21 CFR Part 820) or international equivalents (EU MDR, ISO 13485). This article does not address full regulatory compliance pathways. Engage regulatory counsel and your institution’s IRB/ethics committee before beginning any medical AI project.
Table of Contents
Preparing Your Dataset
Gathering and curating medical text data
High-quality, rights-cleared medical text is the foundation. We typically blend:
- Electronic Health Records (EHRs): Notes, problem lists, meds, labs, and discharge summaries from partner systems. For research, MIMIC-III (critical care) and the newer MIMIC-IV with clinical notes are strong starting points. Important: Verify you have appropriate data use agreements, IRB approvals, and patient consent/authorization before accessing any EHR data.
- Clinical Trials Data: Protocols and results from ClinicalTrials.gov provide structured clinical language and outcomes.
- Medical Literature: PubMed and PubMed Central Open Access Subset articles, MedLine abstracts, and guidelines capture evidence-based phrasing. Ensure compliance with copyright and licensing terms for all sources.
- Medical Transcripts: De-identified dictations and doctor–patient dialogues help with conversational and instruction-tuned use cases. Must undergo rigorous de-identification per HIPAA Safe Harbor or Expert Determination methods.
We also add weak supervision signals (e.g., labeling functions) and metadata like specialty, encounter type, and document section (HPI, Assessment/Plan) to improve downstream control.
Data Governance Requirements:
- Establish data lineage documentation for all sources
- Maintain audit trails of data access and transformations
- Implement version control for datasets
- Document exclusion criteria (e.g., pediatric data if model not intended for pediatrics)
- Conduct bias assessment on source data demographics
Useful resources: MIMIC-III on PhysioNet, PubMed Central, and ClinicalTrials.gov.
Anonymizing and formatting data for training
Under HIPAA/GDPR, strict de-identification is non-negotiable. We combine rule-based and ML de-ID:
- Remove/obfuscate direct identifiers (names, MRNs, SSNs, phone numbers, addresses) and quasi-identifiers (dates, small geo areas) via tools like Philter plus custom regex and dictionary checks. Keep an expert-in-the-loop review for edge cases. HIPAA requires either Safe Harbor (removal of 18 identifier types) or Expert Determination (formal privacy expert attestation that re-identification risk is very small). Refer to HHS guidance on de-identification methods for comprehensive requirements.
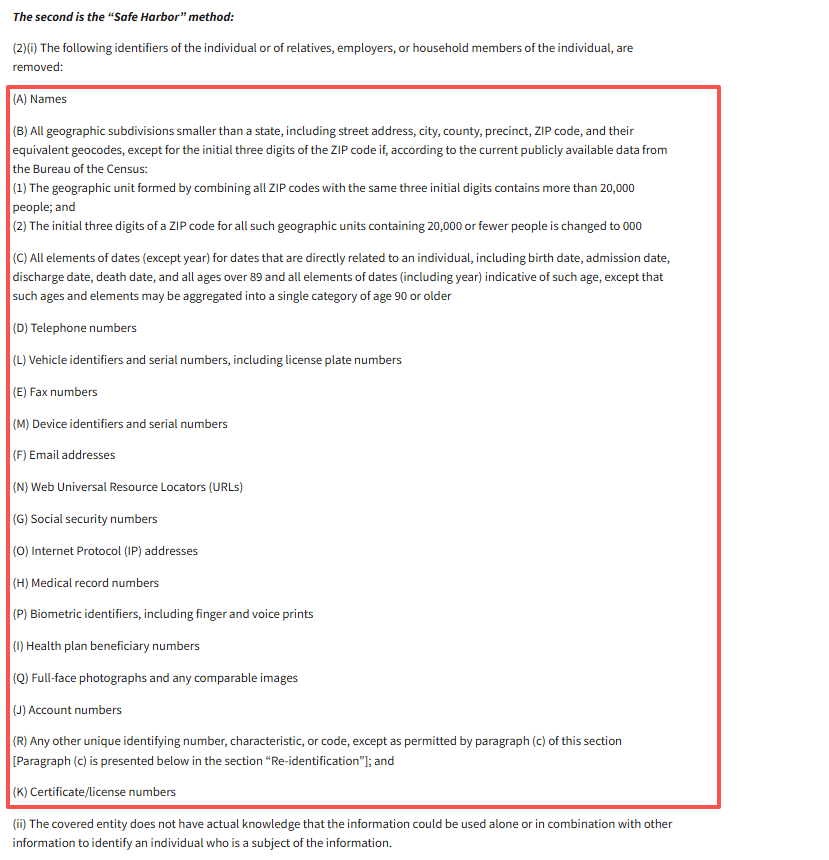
- Apply date-shifting and consistent pseudonyms per patient to retain longitudinal structure without re-identification risk.
- Log de-ID coverage and residual risk: store linkage keys separately with strict access controls. Conduct regular audits to verify no PHI leakage. Recent systematic reviews of clinical text de-identification methods provide benchmarking data.
- For GDPR compliance, document legal basis for processing (Article 6), implement data minimization, and ensure data subject rights mechanisms (access, deletion, portability).
For model-ready formatting:
- Normalize to JSONL or Parquet with fields such as text, task label, specialty, and provenance. Maintain tokenization settings (e.g., WordPiece/BPE) in version control.
- Segment notes into sections and sentences: preserve clinical abbreviations: avoid aggressive stemming that distorts medical terms.
- Create train/validation/test splits by patient to prevent leakage. Capture distribution stats (note length, specialties, class balance) for monitoring drift later. Document demographic distributions (age, sex, race/ethnicity, geography) to enable bias auditing.
Additional Privacy Safeguards:
- Implement differential privacy techniques where feasible to add mathematical privacy guarantees
- Conduct re-identification attack simulations before deployment
- Establish breach notification procedures per HIPAA/GDPR requirements
- Limit data retention periods with automated deletion policies
Reference: HIPAA guidance on de-identification and expert determination.
Fine-Tuning Process
Choosing a base model and setup environment
We start with strong biomedical checkpoints to reduce data and compute needs:
- BioBERT, ClinicalBERT, and BlueBERT for encoder tasks (classification, NER, retrieval).
- For generative tasks (summarization, reasoning, instructions), domain-adapted LLMs such as BioMistral-7B, OpenBioLLM-8B and 70B, Meditron-70B, or Me-LLaMA 13B/70B or general models (e.g., GPT-class, Llama-class) with biomedical continued pretraining can work well when paired with retrieval. Warning: Generative models pose higher hallucination risk. Require extensive validation before clinical use.
Model Selection Considerations:
- Review model licenses for commercial/clinical use restrictions
- Assess model size vs. latency requirements for clinical workflows
- Evaluate whether model training data includes medical content (reduces domain gap)
- Document model provenance and known limitations
Environment: containerized training on AWS, Google Cloud, or Azure with GPUs/TPUs. We standardize on CUDA/ROCm images, enable mixed precision, and track runs with experiment managers (Weights & Biases/MLflow). For privacy, use VPC peering, encrypted storage (KMS-managed), and private registries. Ensure cloud providers have executed Business Associate Agreements (BAAs) for HIPAA compliance. Verify data residency requirements for international regulations.
Resources: BioBERT repo: Google Cloud AI Platform.
Training parameters and techniques
- Hyperparameters: Start with small learning rates (e.g., 1e-5–3e-5 for BERT-class), batch sizes tuned to GPU memory with gradient accumulation, and dropout 0.1–0.3. Use cosine decay or linear warmup. Search via Bayesian optimization rather than exhaustive grids. Document all hyperparameters in model cards for reproducibility and regulatory review per FDA’s Good Machine Learning Practice guidelines.
- Transfer learning: Freeze lower layers initially, then unfreeze progressively (discriminative LRs) to preserve general biomedical knowledge.
- Instruction tuning and RAG: For generative use cases, pair fine-tuning with retrieval-augmented generation over curated corpora (guidelines, local policies) to control hallucinations and support citations. RAG significantly reduces but does not eliminate hallucination risk. Always implement confidence thresholds and abstention mechanisms.
- Regularization: Early stopping on clinical validation loss: label smoothing for noisy labels: data augmentation (section shuffling, template paraphrases) without changing medical meaning. Carefully validate that augmentation doesn’t introduce clinical inaccuracies.
- Safety heads: Add abstention via selective prediction or conformal risk control, so the model can say “uncertain, escalate.” This is critical for medical AI – models must refuse to answer when confidence is low.
Essential Safety Mechanisms:
- Implement confidence calibration to ensure predicted probabilities reflect true accuracy
- Add safety classifiers to detect out-of-distribution inputs
- Build explicit “defer to human” pathways for edge cases
- Log all training instabilities (loss spikes, gradient explosions) for investigation
- Conduct adversarial training against common input perturbations (typos, OCR errors)
References: practical guides on BERT fine-tuning and hyperparameter optimization.
Model Validation in Healthcare
⚠️ Validation Requirements: Medical AI requires significantly more rigorous validation than consumer AI. Insufficient validation is the leading cause of AI-related patient harm. Budget 30-50% of project time for validation.
Evaluating accuracy on clinical data
We evaluate per task, with strong emphasis on calibration and factuality:
Metrics: Precision/Recall/F1 for NER and classification: ROC-AUC and PR-AUC for imbalanced problems: exact match and Rouge for summarization: Brier score and Expected Calibration Error (ECE) for confidence reliability. For medical applications, prioritize recall (minimize false negatives) for serious conditions, and precision (minimize false positives) for follow-up actions that burden patients.
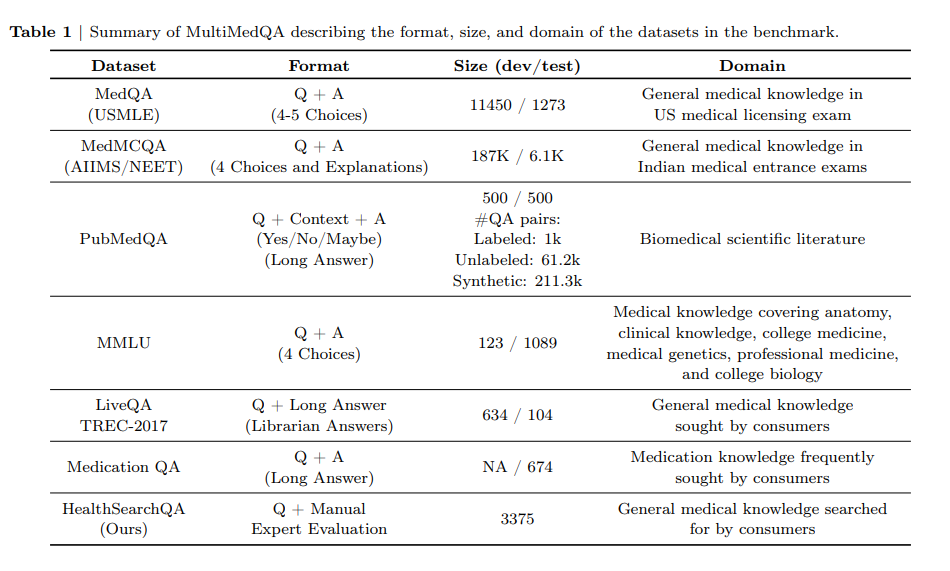
Clinical benchmarks: Consider PubMedQA, MedQA (USMLE-style questions), BioASQ biomedical challenge, and RadGraph F1 for information extraction: but always include site-specific test sets reflecting your actual workflows, patient populations, and EHR systems. External benchmarks may not reflect real-world performance. The MultiMedQA benchmark provides comprehensive evaluation across multiple medical tasks.
Hallucination and grounding: Track citation grounding rate (answers supported by retrieved evidence), Evidence F1, and unsupported-claim rate using frameworks like MedHallu for detecting medical hallucinations. Penalize answers without references when RAG is enabled. In medical contexts, even a 1% hallucination rate may be unacceptable depending on use case. Establish explicit acceptable error rates with clinical stakeholders.
Human evaluation: Dual-annotator reviews (clinician + data scientist) for clinical correctness, with adjudication. Use 5-fold cross-validation to ensure robustness. Require board-certified clinicians in relevant specialties for clinical validation. Inter-rater agreement (Kappa > 0.8) should be documented.
Additional Validation Requirements:
- Prospective validation: Test on future data, not just retrospective sets
- External validation: Test at sites not involved in training
- Temporal validation: Test across different time periods to detect concept drift
- Failure mode analysis: Systematically catalog types of errors and their clinical consequences
- Clinical outcome validation: Where possible, measure impact on patient outcomes, not just technical metrics
- Comparative validation: Benchmark against clinician performance or existing tools
Reference: clinical text classification metrics literature.
Addressing overfitting, bias, and edge cases
- Overfitting: Monitor train–validation gap, apply dropout/weight decay, and cap epochs. Use note-level and patient-level splits to avoid leakage. Test on held-out hospitals/time periods to verify generalization.
- Bias and fairness: Audit performance by sex, age bands, race/ethnicity, language, and site. Report subgroup F1 deltas and equalized odds gaps. Balance data or reweight: consider counterfactual data augmentation (gender-neutral terms, name swapping) where appropriate. Healthcare disparities are pervasive. Disproportionate errors on minority groups can worsen health inequities. Document any observed disparities and mitigation strategies per clinical AI fairness frameworks. Consider impact assessments per AAPOR or equivalent frameworks.
- Edge cases: Curate rare condition sets (e.g., atypical presentations, rare labs) and adversarial inputs (OCR noise, shorthand). Stress-test with shift scenarios (new EHR templates, new drug names). Document known-failure modes and escalation rules. Establish clinical safety thresholds for deployment.
Critical Edge Cases Requiring Special Attention:
- Pediatric vs. adult populations (physiologic differences)
- Pregnancy and postpartum status
- Multi-morbidity and polypharmacy
- Rare diseases and atypical presentations
- Language/translation errors
- Emergency vs. routine care contexts
- Incomplete or missing data patterns
Deployment Strategies
⚠️ Regulatory Note: Deployment of medical AI often triggers regulatory requirements. In the US, FDA regulates Software as a Medical Device (SaMD) under 21 CFR 820. The FDA’s guidance on predetermined change control plans provides pathways for updating AI/ML models post-deployment. In the EU, AI systems for medical purposes fall under the Medical Device Regulation (MDR) and the EU AI Act (high-risk category). Requirements may include:
- Clinical trials demonstrating safety and effectiveness
- Quality management systems (ISO 13485)
- Post-market surveillance
- Adverse event reporting
- Clinical validation studies
Consult regulatory experts early. The pathway depends on intended use, risk classification, and user population. This article does not constitute regulatory guidance.
Cloud vs on-premise deployment
- Cloud (e.g., SageMaker, Azure ML, Vertex AI): Fast spin-up, autoscaling, managed monitoring, and CI/CD hooks. Use private networking, CMEK encryption, and PHI-safe object stores. Some orgs still restrict PHI in public cloud, confirm BAA coverage, HITRUST certification, and data residency requirements. Review AWS HIPAA eligible services, Azure HIPAA and BAA compliance, and Google Cloud HIPAA compliance for up-to-date service listings. Some jurisdictions prohibit PHI in public cloud entirely.
- On-premise/private cloud: Kubernetes or OpenShift with GPU nodes, NVIDIA Triton or vLLM for serving, and Istio for mTLS. Higher control and locality for PHI, but more ops burden. We often start in cloud with synthetic data, then migrate on-prem for PHI workloads. Document security controls: network segmentation, access controls, encryption at rest/in transit, vulnerability management, patch management.
Deployment Security Checklist:
- Penetration testing by qualified security firms
- HIPAA Security Rule compliance audit (administrative, physical, technical safeguards)
- Incident response plan including breach notification procedures
- Role-based access control (RBAC) with least privilege
- Multi-factor authentication for all access
- Audit logging of all model predictions and data access
- Disaster recovery and business continuity planning
Reference: AWS ML deployment overviews and analyses on on-prem AI in healthcare.
Integration with hospital systems and APIs
- FHIR APIs: Read/write via SMART on FHIR scopes: map model inputs to FHIR resources (DocumentReference, Observation, Condition) and attach provenance. Include model version, confidence scores, and timestamps in provenance for traceability.
- HL7 v2: For legacy feeds (ADT, ORU), consume via interface engines (e.g., Rhapsody, Mirth). Normalize to an internal schema before inference.
- App surfaces: Embed in EHR (SMART app, CDS Hooks cards), or expose a REST/gRPC service with audit logging. Enforce role-based access, consent checks, and full request–response logging for compliance. Design UX to clearly distinguish AI recommendations from clinician decisions. Avoid alert fatigue – target high-value, actionable insights only.
Clinical Workflow Integration Best Practices:
- Involve end-user clinicians in design from the beginning
- Minimize clicks and cognitive burden
- Provide explainability: show why the model made its prediction
- Enable easy override/dismissal with feedback capture
- Integrate into existing clinical decision support frameworks
- Establish clear clinical ownership and escalation pathways
- Pilot in low-risk settings before broad rollout
Monitoring and Maintenance
⚠️ Critical: Medical AI requires continuous monitoring. Model drift, data shift, and evolving medical knowledge mean yesterday’s safe model may be unsafe today. Budget for ongoing validation and maintenance.
Continuous performance monitoring
Production is where models drift. We:
- Track input distributions (note length, specialty mix), output metrics (F1, AUC), and calibration (ECE) over time. Alert on threshold breaches. Establish control charts with statistically significant drift detection.
- Monitor hallucinations: unsupported-claim rate, citation coverage, and refusal/abstention behavior. Sample-and-review with clinicians weekly initially, then monthly once stable. Document all clinically significant errors in a centralized safety database.
- Security and privacy: PHI leakage scans on outputs, adversarial prompt tests, rate-limits, and anomaly detection. Maintain immutable audit trails. Implement automated PHI detection in outputs. Log all unusual query patterns.
- Shadow and canary: Run new models in shadow against live traffic: promote via canary with rollback on metric regressions. Require clinical review of shadow results before promotion. Establish automatic rollback triggers for safety metrics.
Additional Monitoring Imperatives:
- User feedback mechanisms: clinicians must be able to easily report errors
- Safety event tracking: near-misses, adverse events, complaints
- Usage analytics: adoption rates, override rates, user satisfaction
- Clinical outcome tracking: measure impact on patient care, not just technical metrics
- Regulatory compliance monitoring: audit trail completeness, access control violations
- Third-party dependency monitoring: track updates to base models, libraries, infrastructure
Reference: articles on model drift monitoring.
Updating models and re-validation
- Continuous training: Schedule retraining with newly de-identified notes and updated guidelines. Re-freeze stable layers to limit catastrophic forgetting. Establish minimum validation requirements before any model update. New versions do not automatically improve safety.
- Versioning and gates: Every model version ships with a model card, test suite, bias audit, and data lineage. Require non-inferiority on core KPIs and reduced hallucination rate before release. Clinical sign-off is mandatory for production deployment.
- A/B testing: Randomize by unit (site/clinician) to avoid contamination: measure task completion time, override rate, and safety events. Power calculations required to detect clinically meaningful differences. Monitor for early safety signals that trigger stopping rules.
- Periodic re-certification: Re-run privacy, security, and clinical validation per policy: update DPA/BAA inventories and documentation. Most regulatory frameworks require annual or more frequent re-validation. Stay current with evolving medical standards of care.
Model Update Governance:
- Change control board with clinical, technical, compliance, and legal representation
- Documented testing and validation procedures
- Rollback procedures for rapid response to safety issues
- Communication plan for clinician users about changes
- Version control and reproducibility for all deployed models
When NOT to Deploy:
- Validation metrics below pre-specified safety thresholds
- Significant bias detected in protected subgroups without mitigation
- Unable to achieve adequate explainability for clinical context
- Regulatory requirements not met or unclear
- Clinical stakeholders not confident in system safety
- Inadequate resources for ongoing monitoring and maintenance
- Edge case coverage insufficient for patient population
Conclusion
When we fine-tune a medical AI model this way, with tight data governance, rigorous validation, disciplined MLOps, continuous clinical oversight, and appropriate regulatory compliance, we get deployable systems that clinicians can trust and compliance teams can approve.
However, medical AI deployment is a journey, not a destination. Patient safety must remain the paramount concern at every stage. No technical article can substitute for:
- Multidisciplinary team collaboration (clinicians, data scientists, ethicists, legal, compliance)
- Robust institutional governance and oversight
- Regulatory guidance and approvals where required
- Ongoing vigilance and willingness to pause or roll back systems when safety concerns arise
The guidance in this article represents technical best practices but does not guarantee regulatory compliance or clinical safety. Always engage appropriate experts for your specific use case and jurisdiction.
About This Article
This technical playbook is intended for informational purposes only. Healthcare organizations should establish their own policies and procedures with guidance from qualified legal, regulatory, clinical, and technical experts appropriate to their specific context.
Medical AI is a rapidly evolving field. Standards, regulations, and best practices change frequently. Readers should consult current authoritative sources and subject matter experts before implementing any medical AI system.
Last Updated: November 20, 2025




